How to develop your first LLM app? Context and Prompt Engineering

In this tutorial, we will develop a simple LLM-based application for rehearsal. We will supply text to the app, like a chapter of the book, and the app will ask us a question about the text, provide several answer choices, and check our answers.
For this tutorial, you need basic coding skills and a basic understanding of LLM. If you're entirely new to LLMs — check out my intro article.
How to start development with LLM?
We will also be using Docker to run the LLM server, so please install it if needed.
Example code is available here.
Start Ollama Server
First, we need to start an LLM to process our requests. A small LLM will work for this task so that we can run one locally. Ollama makes the job easy for us. Let's start an Ollama server and serve a popular LLama3 model.
docker run -p 11434:11434 -it --name ollama --rm ollama/ollama:latest
docker exec ollama ollama pull llama3.1
We're using a small model so that it will run fine on most laptops and PCs. However, if you want to use a bigger model and want to leverage GPU acceleration, don't forget to add --gpus all flag to the docker run command above.
Once the model is downloaded, check that the server is working.
curl http://localhost:11434/api/generate -d '{
"model": "llama3.1",
"prompt": "Explain large language models"
}'
You should see the output like this — this is LLM streaming response a few tokens at a time.
{"model":"llama3.1","created_at":"2024-09-23T17:55:42.022325961Z","response":"Large","done":false}
{"model":"llama3.1","created_at":"2024-09-23T17:55:42.144839461Z","response":" Language","done":false}
{"model":"llama3.1","created_at":"2024-09-23T17:55:42.241879045Z","response":" Models","done":false}
{"model":"llama3.1","created_at":"2024-09-23T17:55:42.336109545Z","response":" (","done":false}
{"model":"llama3.1","created_at":"2024-09-23T17:55:42.428630128Z","response":"LL","done":false}
{"model":"llama3.1","created_at":"2024-09-23T17:55:42.526459087Z","response":"Ms","done":false}
{"model":"llama3.1","created_at":"2024-09-23T17:55:42.689731587Z","response":")","done":false}
{"model":"llama3.1","created_at":"2024-09-23T17:55:42.793133545Z","response":" are","done":false}
{"model":"llama3.1","created_at":"2024-09-23T17:55:42.885699253Z","response":" a","done":false}
{"model":"llama3.1","created_at":"2024-09-23T17:55:42.995663753Z","response":" type","done":false}
{"model":"llama3.1","created_at":"2024-09-23T17:55:43.092215212Z","response":" of","done":false}
{"model":"llama3.1","created_at":"2024-09-23T17:55:43.186611045Z","response":" artificial","done":false}
{"model":"llama3.1","created_at":"2024-09-23T17:55:43.281500379Z","response":" intelligence","done":false}
(Optional) Start Remote Ollama Server
If your hardware is not powerful enough to run the model, or you want to try a bigger model (check out my follow-up article with a more powerful DeepSeek model being tested), you should start a remote server.
There are plenty of options when it comes to serving LLMs. The solution below describes a self-hosted option which is good if you want to ensure that your data is not shared with third parties or if you plan to customize the model or the hosting server. Otherwise, you may want to explore LLM-as-a-service providers like OpenAI, Anthropic, Google Gemini and so on.
Here is how you can do this quickly and cost-effectively with CloudRift GPU rental service (my current gig):
-
Register at cloudrift.ai and add some balance — $20 will be more than enough for occasional use.
-
Click "New" in the console and select "Container Mode."

-
Choose the cheapest GPU — any GPU on the platform is good enough for the small model we're using in this tutorial.
-
Select "Recipes" and "LLama-3.1" from the list of available recipes.
The server will be ready in about ten seconds. Note the IP address, as we'll be using that.
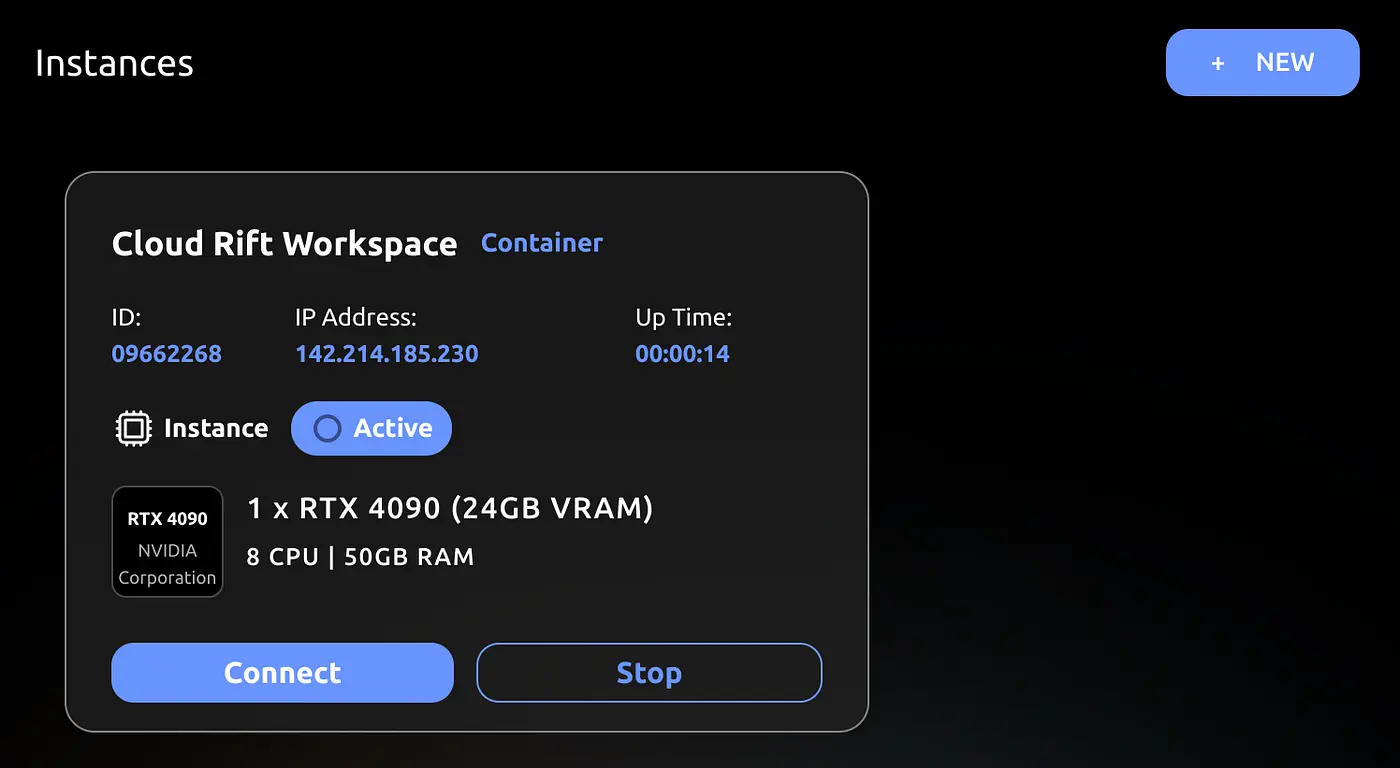
To check that the server is working — run the following command in the console, substituting the IP address with the rented machine address from the console page.
curl http://<IP_ADDRESS>:11434/api/generate -d '{
"model": "llama3.1:8b",
"prompt": "Explain large language models and make it rhyme",
"stream": false
}'
Throughout the tutorial:
-
The http://<IP_ADDRESS>:11434/api/generate should be used as the API address
-
The llama3.1:8b should be used as model when making API calls.
What is Prompt Engineering?
The easiest way to make the LLM process the information the way you want is to use prompt engineering. Likely, you've already used ChatGPT to extract bullet points from a large email or summarize a big text. Here, we will do the same, but programmatically.
To start, supply instructions in the prompt. Let's modify our test prompt to get the behavior we want:
curl http://localhost:11434/api/generate -d '{
"model": "llama3.1",
"prompt": "Explain large language models and make it rhyme",
"stream": false
}'
We've specified "stream": false an option so that Ollama will send us all the text at once. It will be in the response field of the resulting JSON. The result will be a few couples like this:
Large language models, a wonder to see, Trained on vast data, they learn with glee! These AI marvels process words with ease, Creating insights that bring knowledge to seize.
What is Context?
You often want LLM to remember some information when answering queries. Otherwise, we would not be able to converse with them.
Let's illustrate the problem by submitting a sequence of queries.
curl http://localhost:11434/api/generate -d '{
"model": "llama3.1",
"prompt": "Jane writes articles on Medium",
"stream": false
}'
The output will be a JSON response like this:
{
"model":"llama3.1",
"created_at":"2024-09-23T17:59:37.854723959Z",
"response":"It seems you're trying to start a conversation!\n\nThat's great that Jane writes articles on Medium. Medium is a fantastic platform for writers and readers alike, allowing people like Jane to share their thoughts, experiences, and expertise with a global audience.\n\nWhat would you like to know or discuss about Jane's writing on Medium? Is there something specific you're interested in (e.g., topics she covers, her writing style, how you came across her articles)? I'm here to chat!",
"done":true,
"done_reason":"stop",
"context":[128006,882,128007,271,63602,14238,9908,389,25352,128009,128006,78191,128007,271,2181,5084,499,2351,4560,311,1212,264,10652,2268,4897,596,2294,430,22195,14238,9908,389,25352,13,25352,374,264,14964,5452,369,16483,323,13016,27083,11,10923,1274,1093,22195,311,4430,872,11555,11,11704,11,323,19248,449,264,3728,10877,382,3923,1053,499,1093,311,1440,477,4358,922,22195,596,4477,389,25352,30,2209,1070,2555,3230,499,2351,8173,304,320,68,1326,2637,13650,1364,14861,11,1077,4477,1742,11,1268,499,3782,4028,1077,9908,12106,358,2846,1618,311,6369,0],
"total_duration":9994974171,
"load_duration":54809417,
"prompt_eval_count":15,
"prompt_eval_duration":1288647000,
"eval_count":98,
"eval_duration":8649611000
}
We haven't asked LLM anything, so it responds with a generic conversation starter.
It seems you're trying to start a conversation! That's great that Jane writes articles on Medium. Medium is a fantastic platform for writers and readers alike, allowing people like Jane to share their thoughts, experiences, and expertise with a global audience. What would you like to know or discuss about Jane's writing on Medium? Is there something specific you're interested in (e.g., topics she covers, her writing style, how you came across her articles)? I'm here to chat!
Then we ask LLM what Jane does, and LLM doesn't know how to answer this question because it has no context:
curl http://localhost:11434/api/generate -d '{
"model": "llama3.1",
"prompt": "What does Jane do?",
"stream": false
}'
I don't have any information about someone named Jane. Could you provide more context or details about who Jane is and what you're referring to? I'll do my best to help.
However, you may have noticed that our first response contained a field named "context." It is just a binary blob with information in the LLM internal format, and it will provide LLM with the missing information.
"context":[128006,882,128007,271,63602,14238,9908,389,25352,128009,128006,78191,128007,271,2181,5084,499,2351,4560,311,1212,264,10652,2268,4897,596,2294,430,22195,14238,9908,389,25352,13,25352,374,264,14964,5452,369,16483,323,13016,27083,11,10923,1274,1093,22195,311,4430,872,11555,11,11704,11,323,19248,449,264,3728,10877,382,3923,1053,499,1093,311,1440,477,4358,922,22195,596,4477,389,25352,30,2209,1070,2555,3230,499,2351,8173,304,320,68,1326,2637,13650,1364,14861,11,1077,4477,1742,11,1268,499,3782,4028,1077,9908,12106,358,2846,1618,311,6369,0]
Let's supply it to our second query.
curl http://localhost:11434/api/generate -d '{
"model": "llama3.1",
"prompt": "What does Jane do?",
"context":[128006,882,128007,271,63602,14238,9908,389,25352,128009,128006,78191,128007,271,2181,5084,499,2351,4560,311,1212,264,10652,2268,4897,596,2294,430,22195,14238,9908,389,25352,13,25352,374,264,14964,5452,369,16483,323,13016,27083,11,10923,1274,1093,22195,311,4430,872,11555,11,11704,11,323,19248,449,264,3728,10877,382,3923,1053,499,1093,311,1440,477,4358,922,22195,596,4477,389,25352,30,2209,1070,2555,3230,499,2351,8173,304,320,68,1326,2637,13650,1364,14861,11,1077,4477,1742,11,1268,499,3782,4028,1077,9908,12106,358,2846,1618,311,6369,0],
"stream": false
}'
Now LLM answers our question better:
Since you mentioned Jane writes articles on Medium, it's likely that "Jane" is a pen name or pseudonym for someone who shares their thoughts and experiences through written content. If I had to make an educated guess, Jane might be:
- A blogger: She writes articles on various topics, possibly related to her interests, expertise, or personal experiences.
- A writer/journalist: She covers news, trends, or stories in a specific niche or industry, sharing her insights and perspectives with Medium readers.
- An entrepreneur/marketer: Jane might use her writing platform to promote her business, share marketing strategies, or offer advice on entrepreneurship.
- A thought leader/influencer: As someone who shares valuable content on Medium, she could be positioning herself as a trusted expert in her field, sharing her opinions and experiences with others. Of course, without more information, it's impossible to know for sure what Jane does! Would you like me to guess again or would you like to provide some context?
Implement a Simple UI with Gradio
Let's create a skeleton for our application.
Gradio is an extremely simple UI library perfect for small applications like ours. We can install it using pip install gradio command.
Let's implement the app that does the following:
-
Display a text box for the user to supply the text to ask questions about.
-
Once text is supplied — ask a question and provide a few choices for an answer.
-
When a user submits an answer — show whether an answer is correct or not.
Here is the skeleton code for our app.
import gradio as gr
from ollama import Client
def generate_question(text):
# TODO: implement this function
pass
def check_answer(question, choices, selected_choice, correct_answer):
if selected_choice == correct_answer:
return f"✅ Correct! The answer is: {choices[correct_answer]}"
else:
return f"❌ Wrong. The correct answer is: {choices[correct_answer]}"
# UI
with gr.Blocks() as app:
gr.Markdown("# LLM Quiz Generator")
with gr.Row():
text_input = gr.Textbox(
label="Enter text to generate questions from:",
placeholder="Paste a chapter, article, or any text here...",
lines=10
)
generate_btn = gr.Button("Generate Question", variant="primary")
question_output = gr.Textbox(label="Question", interactive=False)
choices_radio = gr.Radio(label="Choose your answer:")
submit_btn = gr.Button("Submit Answer")
result_output = gr.Textbox(label="Result", interactive=False)
# Event handlers
generate_btn.click(
generate_question,
inputs=[text_input],
outputs=[question_output, choices_radio]
)
submit_btn.click(
check_answer,
inputs=[question_output, choices_radio],
outputs=[result_output]
)
if __name__ == "__main__":
app.launch()
Generate Question and Answer Choices
Let's implement the missing generate_question function.
Let's use Ollama Python bindings to make code cleaner, which we can install using the pip install ollama command.
The function does the following:
-
Supply text to the LLM to be used as context.
-
Prompt an LLM to generate a question and a list of answers.
-
Parse LLM output to get the list of questions and a correct answer we can use in the UI.
def generate_question(text):
client = Client(host='http://localhost:11434')
# Step 1: Supply text to the model and get the context
prompt = f"""{text}"""
context = client.generate(model='llama3.1', prompt=prompt)['context']
# Step 2: Generate a question based on the context
prompt = f"""
Generate one question with several answer choices based on the aforementioned text.
Separate the question and answer choices with a newline.
Do not provide any hints, explanations, or additional information.
Use asterisk "*" to denote the correct answer inline.
Don't use asterisk anywhere else and don't repeat the answer to simplify parsing.
"""
response = client.generate(model='llama3.1', prompt=prompt, context=context)['response']
# Step 3: Parse the response
lines = response.split('\n')
question = None
choices = []
correct_answer = 0
for i, line in enumerate(lines):
line = line.strip()
if line == '':
continue
elif question is None:
question = line
else:
if '*' in line:
correct_answer = len(choices)
line = line.replace('*', '')
choices.append(line)
return question, gr.Radio(choices=choices, label="Choose your answer:")
The result
Let's feed the first chapter of the "Treasure Island" by R. L. Stevenson into our application and generate the question. You can grab the text here. The result looks as follows:
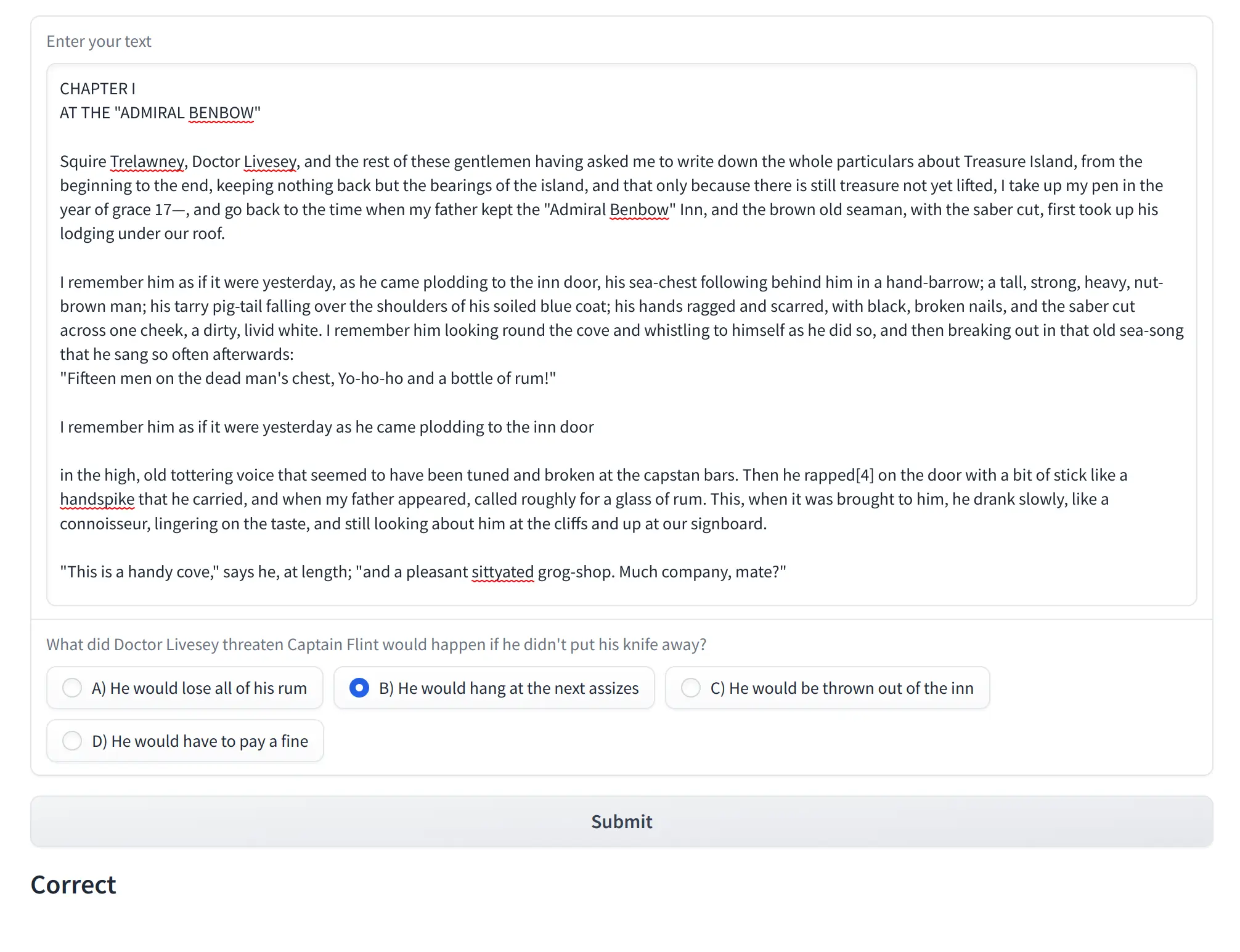
As you can see, LLM generated a sensible question and correctly interpreted the answer. The following sentence in the book confirms it.
The old fellow's fury was awful. He sprang to his feet, drew and opened a sailor's clasp-knife, and balancing it open on the palm of his hand, threatened to pin the doctor to the wall. The doctor never so much as moved. He spoke to him, as before, over his shoulder, and in the same tone of voice, rather high, so that all the room might hear, but perfectly calm and steady: "If you do not put that knife this instant into your pocket, I promise, upon my honor, you shall hang at the next assizes."
Behind the scenes
The app is deceptively simple, but take prompt engineering seriously—it is a powerful tool. It can perform many conventional natural language processing tasks and more. However, when operating any tool, care must be exercised and instructions followed. Let's dig a little bit deeper and answer a few important questions.
Why use context? Couldn't we just supply the text as the part of the prompt?
It is indeed possible. ChatGPT will have no problem generating an answer if we supply text as part of the prompt. However, we're using the smaller, less smart model. We need to make the task more digestible. Separating the context from the query makes it easier for the model to process our request. Otherwise, it is hard for the model to understand what we want from it. There is so much text with so many questions. How would it know which questions it needs to answer? By separating the question for the context, we ensure that LLM is focused on our question.
Can we ask the model to generate JSON output for us to simplify the parsing?
It is also possible. However, LLMs do not think the way we do. They don't understand the structure of a JSON document. They generate something similar to JSON. Thus, they may struggle to produce a well-formatted JSON output, and the parser will occasionally fail. We need to use a bigger or fine-tuned model to make it more reliable.
What to do if LLM doesn't follow the prompt?
This is what the art of prompt engineering is for. Try reformulating the prompt or making it more explicit. For example, the initial prompt used in the demo was "generate a question with several answer choices." However, the model sometimes generated multiple questions. To address that, we need to change the prompt to "generate one question with several answer choices".
When context + prompt engineering is not enough?
The approach above might be too slow if your context is vast or changing rapidly. For example, assume you want to ask LLM questions about the state of your company inventory. Supplying the entire database as context for every query will be too slow! We need to leverage a Retrieval-Augmented Generation (RAG) technique for this use case.
What are other problems with this approach?
Try running the application a dozen times. You'll see that questions and answers are sometimes inaccurate; they look plausible. To address this problem, we need bigger and smarter LLM. However, bigger models are slower and more expensive to run, and you might want to consider fine-tuning a smaller model or "distilling" a bigger model (the process of creating a more efficient model from the big one while retaining its characteristics).
Conclusion
In this tutorial, we learned how to use "Prompt Engineering" to implement basic functionality using LLM and developed a Gradio GUI application for rehearsing.
Example code is available here.
If you enjoyed this article and want to support the team, please join Discord and check out our GPU rental service — cloudrift.ai.
Thanks for reading!


