RTX PRO 6000 vs H100, H200, and L40S: LLM Inference

The race for AI compute is accelerating on two fronts. At one extreme, NVIDIA’s new Blackwell architecture arrives in the form of B200 and B300, designed for hyperscalers training trillion-parameter models with massive HBM stacks, FP8 transformer acceleration, and next-generation NVLink. These chips sit firmly in a league of their own—destined for national labs, cloud giants, and sovereign AI build-outs.
But Blackwell didn’t just land at the ultra-high end. Alongside those megawatt-class datacenter GPUs, NVIDIA introduced something far more accessible: RTX PRO 6000, a workstation-priced card carrying Blackwell-era efficiency, aggressive FP8/INT8 throughput, and high-bandwidth GDDR6. Unlike B200/B300, it targets cost-efficient inference and edge deployments, making it a realistic option for startups, on-prem AI clusters, and regional datacenters.
That affordability raises a compelling question: How close can PRO 6000 get to datacenter GPUs from the previous generation?
In this benchmark, we pit the RTX PRO 6000 against L40S, H100, and H200, comparing throughput and cost per generated token across modern LLM workloads.
Is the RTX PRO 6000 just a budget pretender—or a disruptive alternative to Hopper for inference in 2025?
Benchmarking Setup
My benchmark focuses on maximum throughput for high-concurrency LLM serving scenarios. I tested the following hardware configurations:
- H100: 1x and 8x configurations
- H200: 1x and 8x configurations
- L40S: 2x configuration
- RTX PRO 6000: 1x and 8x configuration
The 8 x H100 SXM a3-highgpu-8d GCP instance is used for running H100 benchmarks.
The 8 x H200 bare-metal instance is supplied by HyperCloud - a prominent cloud provider in Kazakhstan. It is an NVIDIA HGX H200 system featuring Intel(R) Xeon(R) Platinum 8480+ processor. The 2 x L40s VM is rented via their GPU rental console.
The 8 x RTX PRO 6000 Workstation Edition machine is supplied by NeuralRack and features a 64-core EPYC Genoa (4th Gen) processor.
All systems come with loads of RAM and high-speed NVME drivers in RAID0 configuration. The exact hardware specs and system information are included in the benchmark results.
It is worth noting that GPUs come with a different amount of VRAM: 80GB - H100, 96GB - RTX PRO 6000 and 141GB - H200. The models are chosen to fit the minimum available amount of VRAM, i.e. 640GB for 8 x H100 system, but the possibility of using a larger batch size gives advantage to high-VRAM configurations.
Serving Configuration
I optimized the setup for maximum throughput using:
- Inference Engine: vLLM with OpenAI-compatible API
- Tensor Parallelism: Tensor parallelism (
--tensor-parallel-size) for multi-GPU setups - Replica Scaling: Multiple vLLM instances with NGINX load balancing when possible
- Example: On a 8-GPU machine with a model requiring only 1 GPU, I run 8 vLLM instances with NGINX load balancing.
- If all 8 GPUs are required, a single instance with
--tensor-parallel-size=8is used
- Reduced Context Length:
--max-model-len 8192to fit models in memory and improve throughput,--kv-cache-dtype fp8for memory efficiency.
I have also experimented with pipeline parallelism (
--pipeline-parallel-size) for RTX. The PRO 6000 lacks NVLink, thus communication-heavy tensor parallelism might yield slower performance compared to pipeline parallelism. However, the pipeline parallelism resulted in overall lower performance, so I have opted for tensor parallelism for all GPUs.
Benchmark Methodology
I used the vllm bench serve tool with:
- Input/Output Length: 1000 tokens each
- Concurrent Requests: 256 or 512, lower to avoid timeouts on slower configurations, higher to maximize the throughput.
- Request Count: 1024 or 2048 requests per test
- Data: Random synthetic data
Cost Analysis
The GPU prices vary significantly based on the provider, region, SLA, and reservation period. For consistency, I am using an average price from a popular Runpod.io secure cloud service. Note that you can find cheaper options online, like at the cloudrift.ai.
- RTX PRO 6000 WK: $2.09 per GPU per hour. The GPU cost is about $10,000.
- H100 SXM: $2.69 per GPU per hour. The GPU cost is about $30,000.
- H200 NVLINK: $3.39 per GPU per hour. The GPU cost is about $35,000.
- L40S: $0.86 per GPU per hour. The GPU cost is about $9,000.
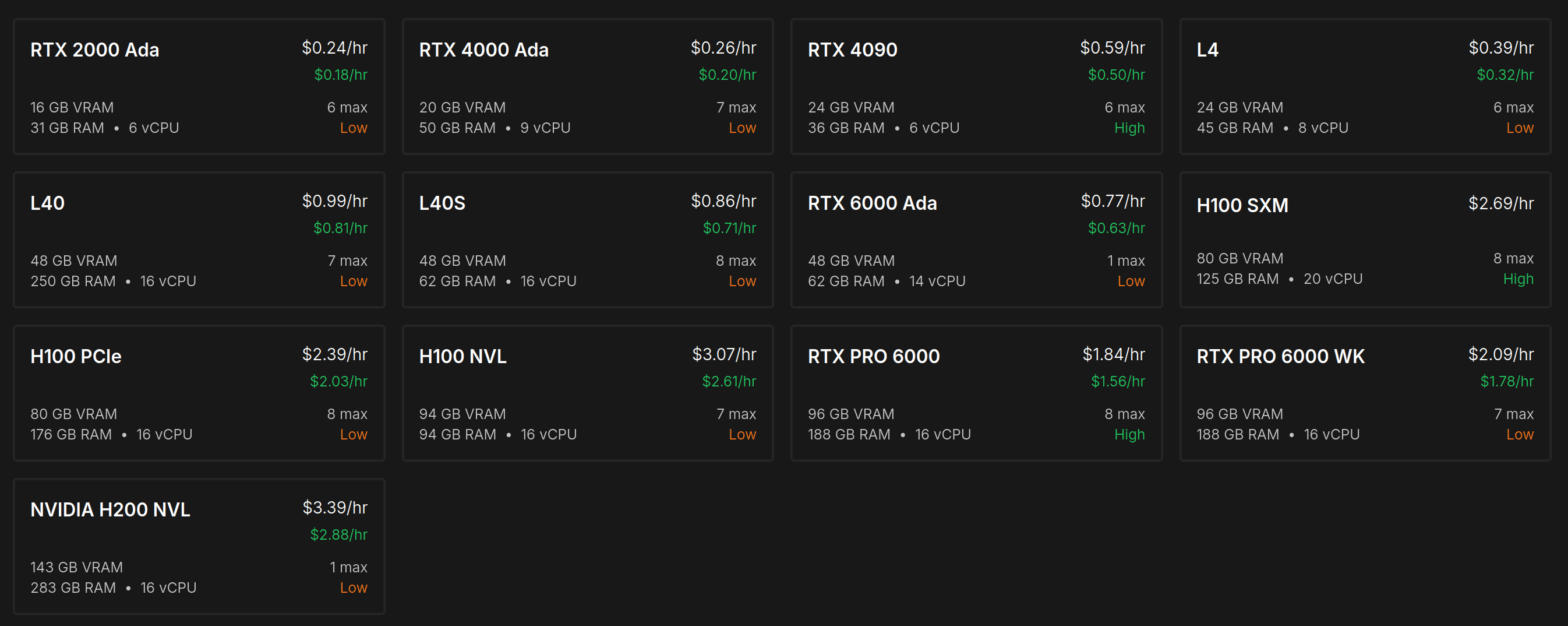
Note on Pricing: The Runpod price for RTX PRO 6000 WK is inflated due to the limited availability of this new GPU. Given that the GPU cost is 1/3 of the H100, the rental price should be around 1/2 of the H100 taking into account fixed elements like electricity, networking, and support. You can rent the RTX PRO 6000 WK for as low as $1.29 per hour on cloudrift.ai at the time of writing.
See current pricing: Compare live GPU rental prices across all configurations and reservation plans.
To better reflect your situation, you can modify these prices in the config.yml file in the benchmark repository and then invoke make report-nov2025 to generate a customized cost analysis.
Model Selection
To understand how PCIe vs NVLink communication affects multi-GPU performance, I've selected three models of increasing size.
1. GLM-4.5-Air-AWQ-4bit (fits 80GB)
This 4-bit quantized model fits comfortably in a single H100 or Pro 6000.
Expected Behavior: Testing maximum throughput with replica scaling. No PCIE bottleneck. The Pro 6000 should demonstrate strong results thanks to Blackwell native support for FP4.
2. Qwen3-Coder-480B-A35B-Instruct-AWQ (fits 320GB)
This 4-bit quantized model requires about four H100 to run.
Expected Behavior: Some PCIe communication overhead in Pro 6000 setups may reduce performance relative to NVLink-enabled datacenter GPUs.
3. GLM-4.6-FP8 (fits 640GB)
This large model requires all eight H100 GPU to run.
Expected Behavior: PCIe communication overhead expected. The H100 and H200 configurations should have an advantage.
Single GPU Performance Benchmark Results
I have run GLM-4.5-Air-AWQ-4bit on single-GPU configurations and two L40S. Each L40S has only 48GB of memory, meaning that we need two GPUs to run the same model that fits in a single H100, PRO 6000, or H200. However, at the price of $0.86 per GPU per hour, the 2x L40S remains a viable contender.
Analysis: This is where RTX PRO 6000 truly shines. Without inter-GPU communication overhead, PRO 6000 actually outperforms the H100 in raw throughput (3,140 vs 2,987 tok/s) while costing 22% less per hour. The result is a 28% lower cost per token ($0.18 vs $0.25/mtok). The H200 leads in absolute performance, but PRO 6000 matches its cost efficiency. The 2x L40S, despite being the cheapest hourly option, delivers the highest cost per token due to lower throughput and the need for two GPUs.
High-throughput Benchmark Results
GLM-4.5-Air-AWQ-4bit
This lightweight 4-bit quantized model fits in a single GPU, allowing us to run 8 replicas with NGINX load balancing on each 8-GPU system.
Analysis: The H200 dominates in raw throughput, achieving nearly 2x the performance of the RTX PRO 6000. However, the cost per token is surprisingly close across all configurations. The RTX PRO 6000 delivers competitive cost efficiency at $0.30/mtok compared to H100's $0.31/mtok—a marginal difference that makes the PRO 6000 a viable alternative for this workload.
Note on scaling: Theoretically, the 8-GPU throughput with replica scaling should be exactly 8x the single-GPU throughput. In practice, we observe less than perfect linear scaling (e.g., 8 x PRO 6000 achieves 15,713 tok/s vs 8 × 3,140 = 25,120 tok/s expected). This ~63% scaling efficiency is likely due to NGINX load balancer overhead, request queuing, imperfect choice of batch size and other system bottlenecks that emerge at high concurrency. All machines demonstrate imperfect scaling efficiency.
Qwen3-Coder-480B-A35B-Instruct-AWQ
This 4-bit quantized 480B parameter model requires approximately 320GB of VRAM, utilizing 4 GPUs with tensor parallelism on each system.
Analysis: As model size increases and tensor parallelism becomes necessary, the NVLink advantage of datacenter GPUs starts to show. The H100 achieves 31% higher throughput than PRO 6000, while the H200 more than doubles the PRO 6000's performance. The H200 offers the best cost efficiency at $0.78/mtok, while the PRO 6000 and H100 are nearly tied around $1.01-1.03/mtok.
GLM-4.6-FP8
This large FP8 model requires all 8 GPUs with full tensor parallelism, pushing inter-GPU communication to its limits.
Analysis: This is where the PCIe bottleneck becomes critical. The H100 achieves nearly 3x the throughput of RTX PRO 6000, and the H200 reaches almost 4x. The cost efficiency gap widens dramatically—PRO 6000's $1.72/mtok is more than a double of the H100's $0.76/mtok and H200's $0.72/mtok. For large models requiring heavy inter-GPU communication, NVLink-equipped datacenter GPUs are significantly more cost-effective.
Cost per Million Tokens Summary
| Model | 1 x PRO 6000 | 1 x H100 | 1 x H200 | 2 x L40S |
|---|---|---|---|---|
| GLM-4.5-Air-AWQ-4bit | $0.18 | $0.25 | $0.17 | $0.29 |
| Model | 8 x PRO 6000 | 8 x H100 | 8 x H200 |
|---|---|---|---|
| GLM-4.5-Air-AWQ-4bit | $0.30 | $0.31 | $0.26 |
| Qwen3-Coder-480B-A35B | $1.03 | $1.01 | $0.78 |
| GLM-4.6-FP8 | $1.72 | $0.76 | $0.72 |
RTX PRO 6000 is highly competitive for single-GPU workloads and maintains reasonable efficiency for medium-sized models. However, for large models requiring 8-way tensor parallelism, the lack of NVLink significantly impacts performance, making datacenter GPUs the more cost-effective choice despite their higher hourly rates.
Beyond rental costs, the capital expenditure difference is substantial. An RTX PRO 6000 costs approximately $10,000 compared to $30,000 for an H100 and $35,000 for an H200. Building an 8-GPU PRO 6000 system costs roughly $80,000 in GPUs alone, while an equivalent H100 system runs $240,000—three times the price. For organizations building on-premises infrastructure or colocation deployments, this makes the PRO 6000 a compelling choice for workloads where it performs competitively.
Conclusion
So, is the RTX PRO 6000 an H100 killer? It certainly beats the H100 PCIe, but when it comes to the SXM version of H100, the answer depends on your workload.
For single-GPU workloads, RTX PRO 6000 is a clear winner—and arguably an H100 killer. Remarkably, the PRO 6000 with GDDR7 memory outperforms even the H100 SXM with its HBM3e in single-GPU throughput (3,140 vs 2,987 tok/s), while delivering 28% lower cost per token ($0.18 vs $0.25/mtok). The Blackwell architecture's native FP4 support and 96GB of VRAM make it excellent for quantized models that fit in a single GPU.
For medium-sized models requiring 2-4 GPUs, PRO 6000 remains competitive. While it loses some ground to NVLink-equipped datacenter GPUs, the cost efficiency stays within the same ballpark ($1.03 vs $1.01/mtok for Qwen3-480B).
For large models requiring 8-way tensor parallelism, datacenter GPUs pull ahead significantly. Once inter-GPU communication enters the picture, the PRO 6000's PCIe limitation becomes obvious. The H100 and H200's NVLink interconnect delivers 3-4x the throughput of PCIe-bound PRO 6000s. The cost efficiency gap grows from marginal to substantial ($1.72 vs $0.72-0.76/mtok).
The Bottom Line: RTX PRO 6000 is not an H100 killer across all workloads, but it doesn't need to be. For startups, on-prem deployments, and teams running models that fit within 1-2 GPUs, it offers datacenter-class performance at workstation prices. At one-third the GPU cost ($10k vs $30k), organizations can deploy three times more compute capacity for the same budget. The key is matching your model size to the interconnect requirements. Use PRO 6000s with smaller models, and reserve H100/H200 clusters for massive models requiring tight GPU coupling.
How to Run This Benchmark Yourself
The complete benchmark code and configuration files are available in the GitHub repository. You can reproduce these results or customize the tests for your specific models and configurations.
Customize the Benchmark
All benchmark parameters are configurable via config.yml:
- SSH servers for remote execution
- Model selection
- GPU configurations
- Concurrency levels
- Input/output lengths
- GPU rental prices (for cost analysis)
After modifying the configuration and specifying server addresses and other parameters, remove files in the results folder and run make bench.
To just generate the report based on the benchmark data, use make report-nov2025.
What's Included
Each benchmark run generates:
- Complete benchmark results with all metrics
- Docker Compose configuration used for serving
- Full benchmark command for reproducibility
- System information and hardware specs
Raw Benchmark Data
All raw benchmark data is available in the repository's results folder. Check out *_vllm_benchmark.txt files for detailed performance metrics and benchmark configuration.
============ Serving Benchmark Result ============
Successful requests: 1024
Maximum request concurrency: 256
Benchmark duration (s): 758.99
Total input tokens: 1022553
Total generated tokens: 1024000
Request throughput (req/s): 1.35
Output token throughput (tok/s): 1349.16
Peak output token throughput (tok/s): 2048.00
Peak concurrent requests: 270.00
Total Token throughput (tok/s): 2696.41
---------------Time to First Token----------------
Mean TTFT (ms): 8804.07
Median TTFT (ms): 2970.55
P99 TTFT (ms): 47041.77
-----Time per Output Token (excl. 1st token)------
Mean TPOT (ms): 180.76
Median TPOT (ms): 185.47
P99 TPOT (ms): 187.61
---------------Inter-token Latency----------------
Mean ITL (ms): 181.04
Median ITL (ms): 147.54
P99 ITL (ms): 1479.28
----------------End-to-end Latency----------------
Mean E2EL (ms): 189379.88
Median E2EL (ms): 188554.39
P99 E2EL (ms): 232323.94
==================================================
============ Docker Compose Configuration ============
services:
vllm_0:
image: vllm/vllm-openai:latest
container_name: vllm_benchmark_container_0
deploy:
resources:
reservations:
devices:
- driver: nvidia
device_ids: ['0', '1', '2', '3', '4', '5', '6', '7']
capabilities: [gpu]
volumes:
- /media/cloudrift/hf_models:/media/cloudrift/hf_models
environment:
- HUGGING_FACE_HUB_TOKEN=
- HF_HOME=/media/cloudrift/hf_models
ports:
- "8000:8000"
shm_size: '16gb'
ipc: host
command: >
--trust-remote-code
--gpu-memory-utilization=0.9
--host 0.0.0.0
--port 8000
--tensor-parallel-size 8
--pipeline-parallel-size 1
--model /media/cloudrift/hf_models/zai-org/GLM-4.6-FP8
--served-model-name zai-org/GLM-4.6-FP8
--tool-call-parser glm45 --reasoning-parser glm45 --max-num-seqs 256 --max-model-len 8192 --kv-cache-dtype fp8
healthcheck:
test: ["CMD", "bash", "-c", "curl -f http://localhost:8000/health && curl -f http://localhost:8000/v1/models | grep -q 'object.*list'"]
interval: 10s
timeout: 10s
retries: 180
start_period: 600s
benchmark:
image: vllm/vllm-openai:latest
container_name: vllm_benchmark_client
deploy:
resources:
reservations:
devices:
- driver: nvidia
count: all
capabilities: [gpu]
volumes:
- /media/cloudrift/hf_models:/media/cloudrift/hf_models
environment:
- HUGGING_FACE_HUB_TOKEN=
- HF_HOME=/media/cloudrift/hf_models
- CUDA_VISIBLE_DEVICES=""
entrypoint: ["/bin/bash", "-c"]
command: ["sleep infinity"]
profiles:
- tools
============ Benchmark Command ============
vllm bench serve
--model zai-org/GLM-4.6-FP8
--dataset-name random
--random-input-len 1000
--random-output-len 1000
--max-concurrency 256
--num-prompts 1024
--ignore-eos
--backend openai-chat
--endpoint /v1/chat/completions
--percentile-metrics ttft,tpot,itl,e2el
--base-url http://vllm_0:8000
==================================================
Future Benchmarks
If you'd like to see specific configurations or models benchmarked, please let me know in the comments or in our Discord community.
Acknowledgments
This benchmark was conducted on servers provided by NeuralRack and HyperCloud, who have kindly provided hardware for this initiative. The benchmark is performed using CloudRift software and infrastructure.
GitHub Repository
Access the complete benchmark code, configuration files, and raw results:
https://github.com/cloudrift-ai/server-benchmark
Related: How Much Does It Cost to Rent RTX PRO 6000?
Based on this benchmark, the RTX PRO 6000 offers exceptional performance at low cost for LLM inference. If you're looking to deploy your own LLM inference workloads:
- RTX PRO 6000 pricing starts at $1.29/hour for single GPU configurations
- Multi-GPU setups (2x and 4x) available for larger models
- Reserved instances offer discounts for longer-term commitments
See our pricing calculator to estimate costs for your specific workload, or launch a console to get started immediately.


