Building a Community LLM Exchange

The Easiest Way to Share your LLM with the World
A proliferation of AI models and model providers has given rise to a new set of challenges. Specifically, how to select the right model and work with multiple models/providers efficiently? To address this problem, a new class of software has emerged: LLM gateways and routers.
The goal of an LLM gateway is to provide a unified API endpoint that abstracts away the differences between various LLM providers. This way, users can send requests to a single endpoint and have them routed to the appropriate provider based on the model, cost, latency, or other criteria. Luckily, the OpenAI API has become the de facto standard for LLM providers, making it easier to build such gateways. A notable self-hosted example is LiteLLM. The LLM router is a more advanced version of the gateway. In addition to providing a unified API endpoint, it also provides advanced routing capabilities. For example, it can automatically route requests based on the model, cost, latency, or other criteria. A notable example is Martian.
The rapid growth in the number of LLM providers has also created a need for marketplaces where users can discover and compare different models and providers. These marketplaces typically provide a catalog of models and providers, along with pricing, performance, and other relevant information. Users can then select the model or provider that best meets their needs. A notable example is OpenRouter or Hugging Face Inference API. It is also possible to combine the two approaches and build a marketplace with a self-hosted open-source option like LLMGateway does.
However, this is one thing to use an LLM gateway or router, but another to get your own LLM endpoint listed on one of these platforms. Adding your endpoint to a popular platform like Hugging Face or OpenRouter is an involved process. They're very selective about what models and endpoints they accept, and the process is opaque. Additionally, you'll need to implement authentication, usage tracking, billing, and load-balancing at a minimum if you want to get paid. Overall, it's a lot of work and can be prohibitively expensive for individuals or small companies.
Initially, I thought that my startup was just too lame to get noticed by these platforms. But then I realized that many other bigger and better-funded companies are in the same boat, not to mention individual researchers. At the most recent AI Infra Summit in Santa Clara, I ran into several companies working on their AI accelerators or other LLM products and willing to offer free access to their hardware in exchange for feedback and testing. Many of the companies providing free access to their hardware are not well-known, and they lack the resources and talent necessary to build a fully-fledged LLM-as-a-service platform, let alone promote it.
Thus, the idea of LLM Exchange was born, a platform that connects LLM providers with users looking for cheap or free access to LLMs. The platform is open to anyone who wants to share their LLM endpoint and anyone who wants to use it. The only requirement is that the provider must provide an OpenAI-compatible API endpoint.
In this article, I'll explain how I built Inferline, a proof-of-concept of such a platform that allows anyone to share their LLM endpoint and anyone to use it for free. Continue reading if you're interested in the idea or want to learn more about building an LLM gateway or LLM model serving.
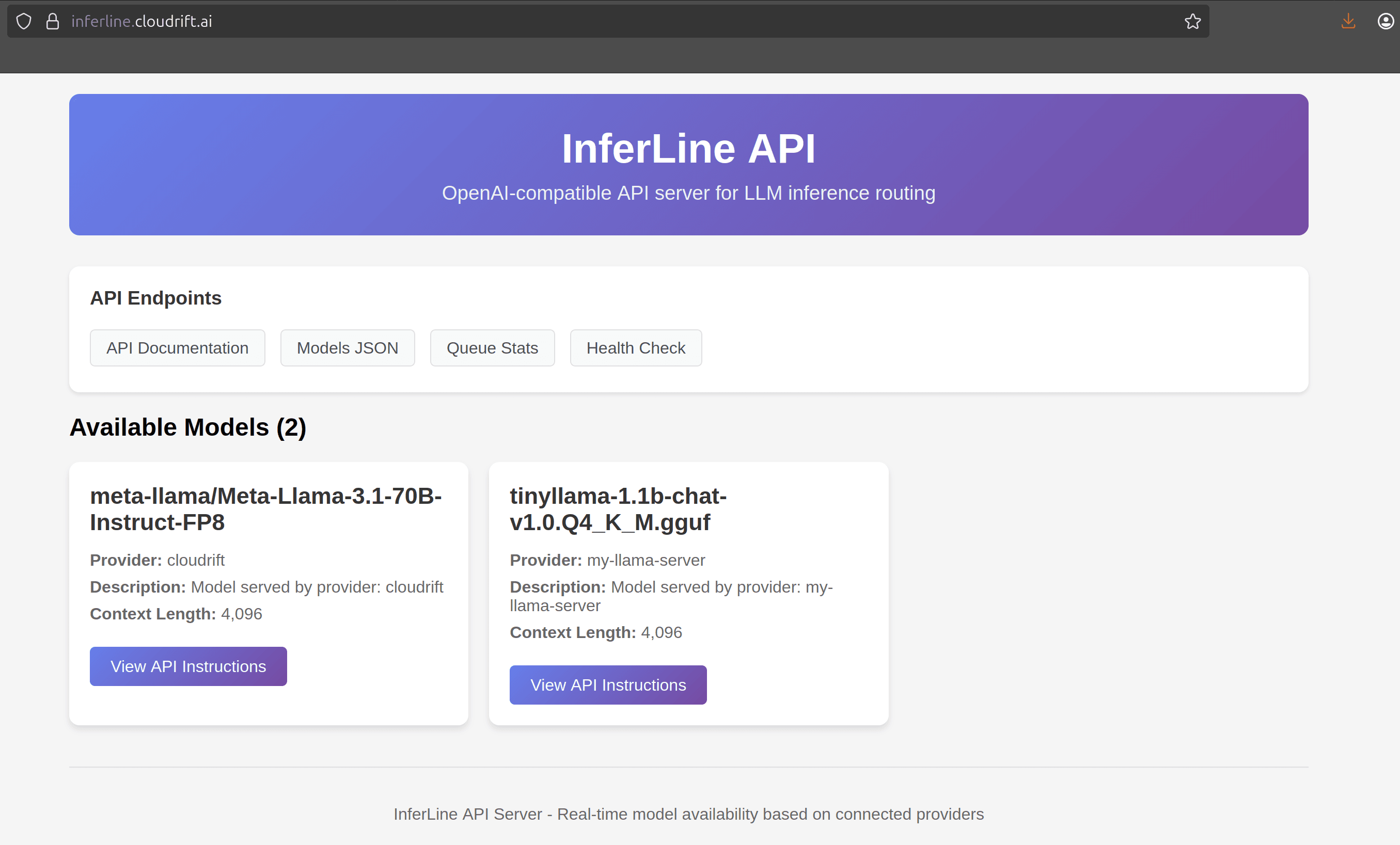
Give me Free Endpoint!
If you're so eager to get your free token generation endpoint, just head to Inferline and start using it right away. No payment, no credit card, not even registration is required. You can start sending requests to the endpoint right away.
How Typical LLM Gateways Work?
One factor that facilitates the aggregation of LLMs is the widespread adoption of the OpenAI API as the standard for LLMs by most providers. This means that you can use the same API to access different models from different providers. The API structure is straightforward to use; for a basic implementation, you need to provide /v1/completions, /v1/chat/completions and /v1/models endpoints, and you're all set. The first two are used for prompting the LLM, and the latter is to report the list of available models. Here is an example of how to use the OpenAI API to send a request to an LLM endpoint.
curl https://api.openai.com/v1/responses \
-H "Content-Type: application/json" \
-H "Authorization: Bearer $OPENAI_API_KEY" \
-d '{
"model": "gpt-5",
"input": "Write a short bedtime story about a unicorn."
}'
Typically, an LLM gateway like LiteLLM works like a proxy server. It provides an OpenAI-compatible API endpoint that users can use to send requests to the LLM. The gateway then forwards the request to the LLM provider's endpoint and returns the response to the user. The gateway and provider servers split responsibilities for handling authentication, rate limiting, load balancing, caching, retries, and billing.
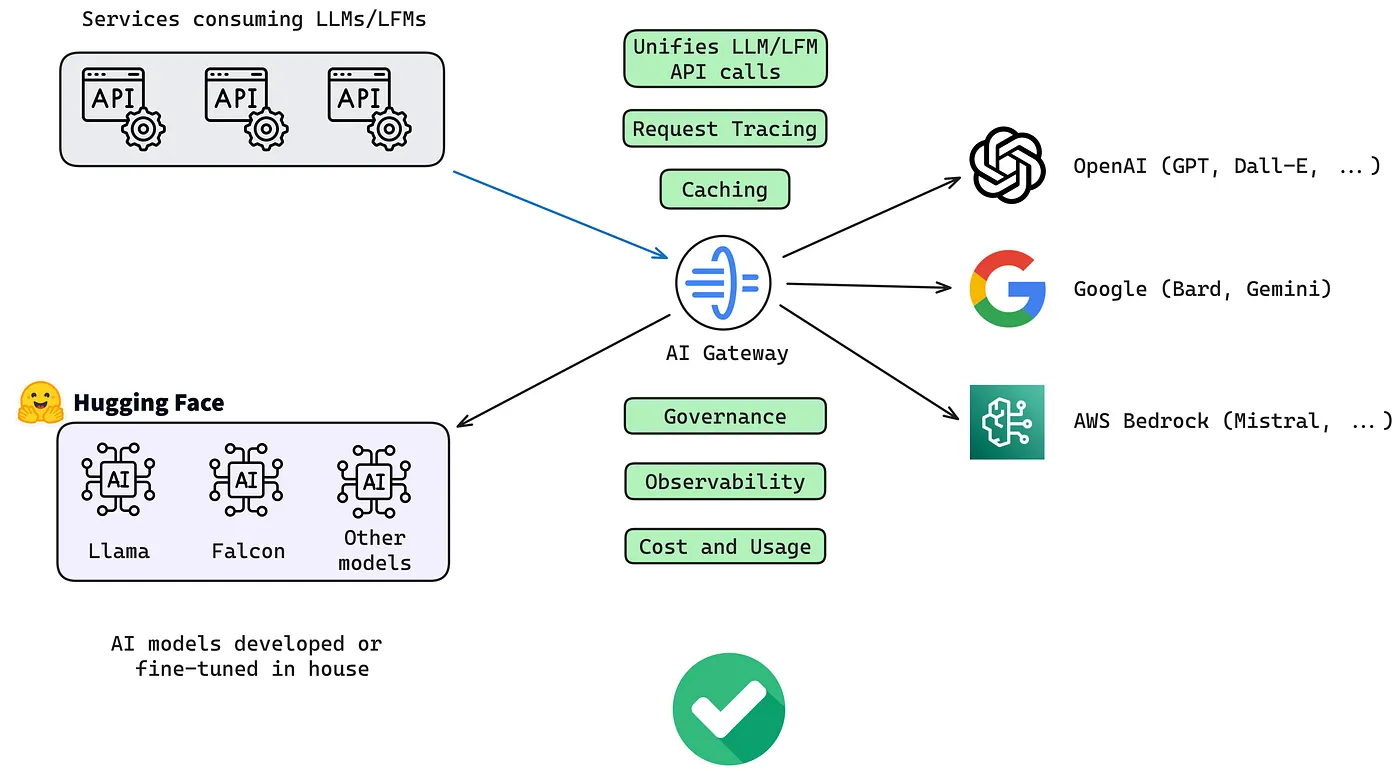
To connect your LLM endpoint to a gateway, you must set up a publicly accessible endpoint that the gateway can access. Additionally, you'll need to handle the authentication, rate limiting, and billing on your own. After that, you need to convince the gateway to add your endpoint to their platform. The gateway will then forward the requests to your endpoint and return the responses to the users. All this is a lot of work, and not many providers are willing to go through this process, especially if they are small companies or individual researchers.
How Inferline Works?
To make it easy for anyone to share their LLM endpoint, I decided to turn the architecture around. Instead of gateway pushing requests to the provider's endpoint, the provider will pull requests from the gateway. This way, the provider doesn't need to set up a publicly accessible endpoint, and the gateway doesn't need to vet the provider's endpoint. Additionally, it makes the load balancing and scaling easier thanks to the natural backpressure, as the provider can control how many requests it wants to pull from the gateway.
The gateway provides a simple API to pull requests from the queue and submit responses. The provider runs a small forwarding agent that pulls requests from the gateway and forwards them to the provider's endpoint. This way, we can continue to use any LLM serving platform that provides an OpenAI-compatible API endpoint, like vLLM, LlamaCPP, or SGLang.
With this architecture, anyone can share their LLM endpoint by simply running a small agent that will pull requests from the gateway and forward them to the provider's endpoint.
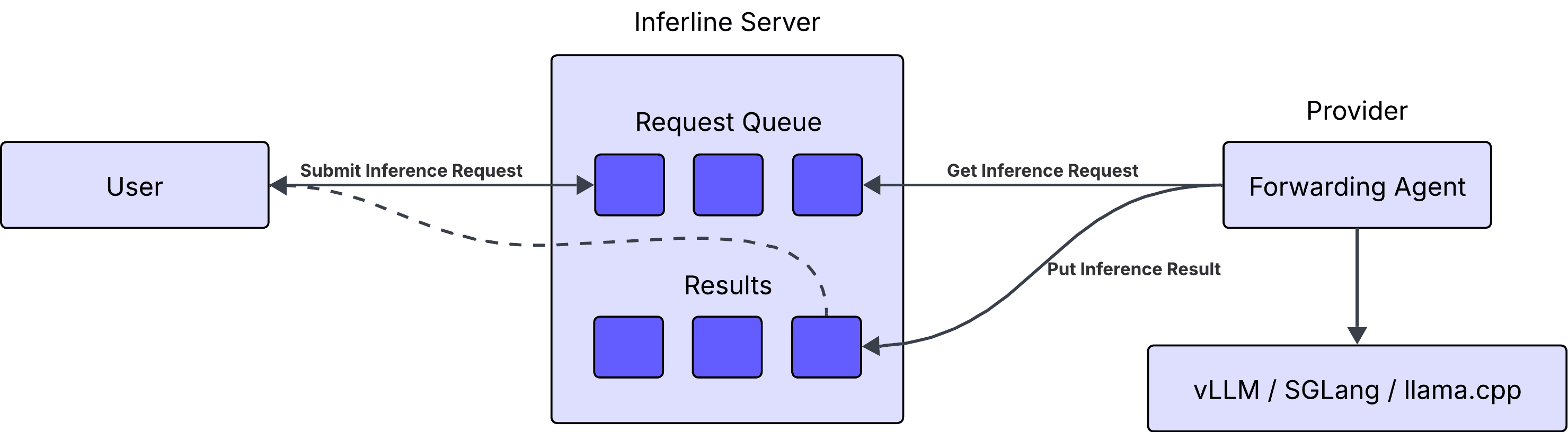
Inferline comes with a Docker Compose file to run a TinyLlama server using llama.cpp and a forwarding agent. To get started, clone the repo and run the following command:
git clone git@github.com:cloudrift-ai/inferline.git
PROVIDER_ID=my-llama-server docker compose -f docker/docker-compose-tinyllama.yml up -d
Once you start the containers, you'll see your endpoint in the Inferline dashboard under the "Providers" tab. You can then begin to send requests to the endpoint.
The Provider
Below is the content of docker-compose-tinyllama.yml file. It contains two services: the TinyLlama model served using llama.cpp and the forwarding agent that will grab requests from the server, forward them to TinyLlama, and send responses back.
version: '3.8'
services:
# TinyLlama server using LlamaCPP
tinyllama:
build:
context: ..
dockerfile: docker/llamacpp-tinyllama.Dockerfile
container_name: tinyllama
ports:
- "8001:8000"
restart: unless-stopped
networks:
- inferline-net
healthcheck:
test: ["CMD-SHELL", "curl -f http://localhost:8000/v1/models || exit 1"]
interval: 10s
timeout: 5s
retries: 5
start_period: 30s
# OpenAI Provider to connect TinyLlama to InferLine
openai-provider:
build:
context: ..
dockerfile: docker/openai-provider.Dockerfile
container_name: tinyllama-provider
environment:
- OPENAI_BASE_URL=http://tinyllama:8000
- OPENAI_API_KEY=not-needed
- INFERLINE_BASE_URL=https://inferline.cloudrift.ai/api
- POLL_INTERVAL=1.0
- MODEL_REFRESH_INTERVAL=60.0
- PROVIDER_ID=${PROVIDER_ID:-tinyllama-provider}
depends_on:
tinyllama:
condition: service_healthy
restart: unless-stopped
networks:
- inferline-net
networks:
inferline-net:
driver: bridge
The tinyllama container runs a standard llama.cpp server that downloads and serves a small 1.1B parameter model. The Dockerfile is as follows. By modifying this Docker file, you can change the model being served.
FROM python:3.11-slim
ENV PYTHONUNBUFFERED=1
RUN apt-get update && apt-get install -y build-essential curl
RUN pip install --upgrade pip && \
pip install llama-cpp-python[server] --extra-index-url https://abetlen.github.io/llama-cpp-python/whl/cpu
WORKDIR /models
RUN curl -L -o /models/tinyllama-1.1b-chat-v1.0.Q4_K_M.gguf \
https://huggingface.co/TheBloke/TinyLlama-1.1B-Chat-v1.0-GGUF/resolve/main/tinyllama-1.1b-chat-v1.0.Q4_K_M.gguf
EXPOSE 8000
CMD ["python", "-m", "llama_cpp.server", \
"--host", "0.0.0.0", \
"--port", "8000", \
"--model", "/models/tinyllama-1.1b-chat-v1.0.Q4_K_M.gguf", \
"--n_ctx", "2048", \
"--n_threads", "4"]
The forwarding agent is a simple Python script that uses the requests library to pull requests from the server and forward them to the local LLM endpoint. The Dockerfile for the agent is as follows.
FROM python:3.11-slim
# Set environment variables
ENV PYTHONUNBUFFERED=1
ENV PYTHONPATH=/app
# Install system dependencies
RUN apt-get update && apt-get install -y curl
# Create app directory
WORKDIR /app
# Copy application code and requirements
COPY pyproject.toml /app/
COPY inferline/ /app/inferline/
# Install Python dependencies after copying code
RUN pip install --upgrade pip && \
pip install -e .
# Create logs directory
RUN mkdir -p /app/logs
# Default command (uses console script entry point)
CMD ["inferline-openai-provider"]
Here is the core logic of the forwarding agent that pulls requests from the server and forwards them to the local LLM endpoint. It does the following:
- Grabs the request from the server using the
/queue/nextendpoint. - Processes the request by forwarding it to the local LLM endpoint. The agent supports both completion and chat completion requests.
- Submits the result or an error back to the server using the
/queue/resultendpoint.
async def _request_processing_loop(self):
"""Main loop to poll for and process inference requests"""
while self.running:
try:
request = await self._get_next_request()
if request:
await self._process_request(request)
else:
await asyncio.sleep(self.poll_interval)
except Exception as e:
logger.error(f"Error in request processing loop: {e}")
await asyncio.sleep(self.poll_interval)
async def _get_next_request(self) -> Optional[QueuedInferenceRequest]:
"""Get the next pending request from inferline queue that we can handle"""
try:
# Create provider capabilities
capabilities = ProviderCapabilities(
provider_id=self.provider_id,
supported_models=self.available_models,
request_types=["completion", "chat"]
)
logger.info(f"Sending capabilities with provider_id: {self.provider_id}")
request_data = QueueRequestWithCapabilities(
provider_capabilities=capabilities,
provider_base_url=self.openai_base_url
)
async with self.session.post(
f"{self.inferline_base_url}/queue/next",
json=request_data.model_dump()
) as response:
if response.status == 200:
data = await response.json()
return QueuedInferenceRequest(**data)
elif response.status == 204:
# No pending requests for this provider
return None
else:
logger.warning(f"Failed to get next request: HTTP {response.status}")
return None
except Exception as e:
logger.error(f"Error getting next request: {e}")
return None
async def _process_request(self, request: QueuedInferenceRequest):
"""Process an inference request by forwarding to OpenAI"""
try:
model = request.request_data.get('model')
# Process based on request type (no need to check model availability - server already filtered)
if request.request_type == "completion":
result = await self._process_completion_request(request)
elif request.request_type == "chat":
result = await self._process_chat_completion_request(request)
else:
await self._submit_error_result(
request.request_id,
f"Unsupported request type: {request.request_type}"
)
return
# Submit successful result
await self._submit_result(request.request_id, result)
except Exception as e:
logger.error(f"Error processing request {request.request_id}: {e}")
await self._submit_error_result(request.request_id, str(e))
async def _process_completion_request(self, request: QueuedInferenceRequest) -> Dict:
headers = {
'Content-Type': 'application/json'
}
if self.openai_api_key:
headers['Authorization'] = f'Bearer {self.openai_api_key}'
async with self.session.post(
f"{self.openai_base_url}/v1/completions",
json=request.request_data,
headers=headers
) as response:
if response.status == 200:
return await response.json()
else:
error_text = await response.text()
raise Exception(f"OpenAI API error {response.status}: {error_text}")
async def _process_chat_completion_request(self, request: QueuedInferenceRequest) -> Dict:
"""Similar to above but for chat completions"""
async def _submit_result(self, request_id: str, result_data: Dict):
"""Submit successful result back to inferline"""
try:
result = InferenceResult(
request_id=request_id,
result_data=result_data,
usage=result_data.get('usage'),
error_message=None
)
async with self.session.post(
f"{self.inferline_base_url}/queue/result",
json=result.model_dump()
) as response:
if response.status == 200:
logger.info(f"Successfully submitted result for request {request_id}")
else:
logger.error(f"Failed to submit result: HTTP {response.status}")
except Exception as e:
logger.error(f"Error submitting result for {request_id}: {e}")
async def _submit_error_result(self, request_id: str, error_message: str):
"""Submit error result back to inferline"""
try:
result = InferenceResult(
request_id=request_id,
result_data={},
usage=None,
error_message=error_message
)
async with self.session.post(
f"{self.inferline_base_url}/queue/result",
json=result.model_dump()
) as response:
if response.status == 200:
logger.info(f"Successfully submitted error for request {request_id}")
else:
logger.error(f"Failed to submit error: HTTP {response.status}")
except Exception as e:
logger.error(f"Error submitting error for {request_id}: {e}")
The Server
The server provides a simple web interface for users to browse and search for available LLM endpoints, as well as an API for the agents to pull requests from the gateway. Internally, the server maintains a queue of requests for each provider, and the agents can pull requests from the queue.
Below is the core logic of the server that handles the queue of requests and the provider registration. It works as follows:
- Provider requests an LLM task.
- The server checks the queue of requests and finds one that the provider can handle, i.e., the request to the model that the provider supports.
- The request is marked as processing, and the server waits for the request to be fulfilled.
- The server cleans up the list of supported models and providers periodically if the provider hasn't been seen for some time.
@app.post("/queue/next", response_model=QueuedInferenceRequest)
async def get_next_inference_request(provider_info: QueueRequestWithCapabilities):
"""Get the next pending inference request that this provider can handle"""
capabilities = provider_info.provider_capabilities
provider_id = capabilities.provider_id
# Clean up inactive models and providers periodically
cleanup_inactive_models()
# Update provider tracking
active_providers[provider_id] = capabilities
provider_last_seen[provider_id] = time.time()
# Find pending requests that this provider can handle
pending_requests = []
for req in inference_queue.values():
if req.status == InferenceStatus.PENDING:
# Check if provider supports the requested model
requested_model = req.request_data.get('model')
request_type = req.request_type
if (requested_model in capabilities.supported_models and
request_type in capabilities.request_types):
pending_requests.append(req)
if not pending_requests:
raise HTTPException(status_code=204, detail="No pending requests for this provider")
# Get the oldest request this provider can handle
oldest_request = min(pending_requests, key=lambda x: x.created_at)
# Mark as processing
oldest_request.status = InferenceStatus.PROCESSING
oldest_request.started_at = datetime.now()
return oldest_request
@app.post("/queue/result")
async def submit_inference_result(result: InferenceResult):
"""Submit the result of an inference request"""
request_id = result.request_id
if request_id not in inference_queue:
raise HTTPException(status_code=404, detail=f"Request {request_id} not found")
queued_request = inference_queue[request_id]
if result.error_message:
queued_request.status = InferenceStatus.FAILED
queued_request.error_message = result.error_message
else:
queued_request.status = InferenceStatus.COMPLETED
# Store the result
results_storage[request_id] = result.result_data
queued_request.completed_at = datetime.now()
return {"message": "Result submitted successfully", "request_id": request_id}
Performance
The performance of this architecture is comparable to that of traditional proxy-like architectures. The main difference is that the provider pulls requests from the server instead of the server pushing requests to the provider. This introduces the need to use queueing and polling mechanisms, which can introduce some latency. On the other hand, it also introduces natural backpressure, as the provider can control how many requests it wants to pull from the server, making the load balancing and scaling easier.
An interesting extension would be a direct integration of Inferline with an inference engine like vLLM. Inference engines have more information about the requests being processed. This information can be used to make more informed decisions about which requests to pull from the server and when to pull them.
Ultimately, the use of LLM gateways and marketplaces is a trade-off between convenience and performance. If you need the best possible performance, you should use the provider's endpoint directly. However, suppose you want the convenience of a unified API endpoint and the ability to switch between different providers easily. In that case, using an LLM gateway or marketplace is the best approach.
Monetization
For this proof of concept, the platform is entirely free to use. However, if you see benefits of enabling the monetization, please let me know, and I will connect the platform to our existing LLM-as-a-Service infrastructure, allowing for monetization.
The server has visibility into input prompts and results; thus, a conventional pay-per-token billing model can be utilized.
Security and Privacy
Given that there is no vetting process for providers, the platform is not suitable for production use and is not guaranteed to be secure or private. Do not send any sensitive data to the platform, as there is no way to verify the security or privacy of the providers.
However, this architecture doesn't introduce additional security challenges compared to the conventional proxy-like architecture. The mechanisms for securing the platform would be precisely the same:
- Vet providers manually to introduce a list of trusted providers. Use common legal agreements and security standards to ensure compliance and safety.
- Implement end-to-end encryption between the user and the provider so that the platform cannot see the data being sent to the provider. To prevent providers from seeing the user data, a technology like NVIDIA Confidential Computing can be used to run the LLM in a secure enclave.
Conclusion
This article presented the idea of an LLM Exchange, a platform that connects LLM providers with users looking for cheap or free access to LLMs. The platform is open to anyone who wants to share their LLM endpoint and anyone who wants to use it. The only requirement is that the provider must provide an OpenAI-compatible API endpoint. No publicly accessible endpoint is required, as the provider pulls requests from the server, making it easy for anyone to share their LLM endpoint.
Please let me know your thoughts on the LLM Exchange idea and if you have any suggestions or feedback. If the idea resonates with you, please star the repo and leave a comment. Or even better, contribute so that we can turn it into a fully-fledged platform together!


