How to Give Your RTX GPU Nearly Infinite Memory for LLM Inference

Network-Attached KV Cache for Long-Context, Multi-Turn Workloads
Let's be honest — we can't afford an H100. Forget the H200. We're not OpenAI. We're just some infrastructure nerds duct-taping GenAI services together with consumer GPUs, spot-instance pricing, and coffee.
The problem? LLMs eat VRAM like it is a free snack — especially for use cases like chatbots or code generation, where you're stuffing complete files, docstrings, and a week's worth of conversation history into every prompt. The 24 GB on a RTX 4090 disappears faster than your cloud credits.
Once that happens, everything goes downhill: cache evictions, redundant computation, bloated latency, GPU thrashing. You can't afford to keep the KV cache in memory, so the model keeps recomputing it. Over. And over. And over. Meanwhile, your user is waiting 2 seconds to autocomplete def.
So we tried something weird: what if we just shoved all the KV cache into NVMe drives and served it over a high-speed network?
Pliops has graciously sent us their XDP LightningAI — a PCIe card that acts like a brainstem for your LLM cache. It offloads all the massive KV tensors to external storage, which is ultra-fast thanks to accelerated I/O, fetches them back in microseconds, and tricks your RTX 4090 into thinking it has a few terabytes of VRAM.
The result? We turned a humble 4 x RTX 4090 rig into a code-generating, multi-turn LLM box that handles 2–3× more users, with lower latency — all while running on gear we could actually afford.
In this post, we'll show you:
- Why your GPU is secretly wasting compute on redundant work
- How KV cache offloading actually works
- How people scale LLMs without hyperscaler budgets
it's an elegant solution, and the main thing is that it simply works with no application friction— and in the race to build cheap, fast, scalable GenAI, we'll take every hack we can get.
You can try the deployed model here
The KV Cache Bottleneck in LLM Inference
Why KV caching matters: Modern Transformer-based LLMs generate text autoregressively, meaning each new token's computation depends on all prior tokens' data. KV caching is a technique that stores the keys and values produced at each transformer layer for past tokens, so they can be reused for the next token instead of recomputed from scratch. Without caching, generating each token would require reprocessing the entire input context and already-generated tokens (quadratic complexity O(n²) per token). KV caches make this linear O(n) after the first token, massively speeding up inference. In latency-critical applications (chatbots, real-time assistants, etc.), this is essential for fast responses.
The challenge of repeated computation: The catch is that KV caches consume a lot of GPU memory. The cache size grows with sequence length (context) and number of concurrent requests. GPUs like the RTX 4090 have limited memory (24 GB), which can quickly be exhausted by prolonged conversations or multiple users simultaneously. In practice, many LLM serving setups do not persist KV caches across user turns or sessions — either due to memory constraints or framework limitations. This means if a user sends a follow-up prompt (or if the model sees a repeated prefix later), the system often recomputes those same keys and values from scratch. Studies have found that an overwhelming portion of context data "even up to 99%" in some workloads — ends up being processed repeatedly in LLM inference. This redundant computation not only increases time-to-first-token (TTFT) (since the model spends time re-processing prior context) but also wastes GPU cycles and power on duplicate work.
Memory vs. latency trade-off: One straightforward way to avoid recomputation is to keep all KV caches in GPU memory for reuse. Frameworks like vLLM offer features such as Automatic Prefix Caching (APC) to retain caches in VRAM between requests. This minimizes TTFT for repeated queries, as the model can skip directly to generating the next token. However, retaining caches in VRAM reduces available memory for new queries or longer contexts, effectively trading capacity for speed. With large models or many concurrent users, caches soon overflow GPU memory, forcing eviction and recomputation.
Disaggregated KV-Cache Offloading
One way to bypass the memory bottleneck is to offload the KV cache to a fast, external NVMe-based tier served over the network. Instead of discarding keys and values when GPU memory fills up, they're written to a remote store and retrieved when needed, allowing GPUs to process each context only once and reuse results in future turns.
This offload happens transparently: when a repeated prefix appears, the system pulls cached KV blocks from the external tier instead of recomputing them. Despite being outside the GPU, access latency remains in the microsecond range thanks to RDMA and I/O optimized in parallel to compute, making time-to-first-token virtually identical to keeping everything in VRAM.
By separating memory from compute, this design allows servers to scale context length and concurrency without scaling GPU count. You effectively get terabytes of cache capacity, while keeping GPU utilization high and costs low.
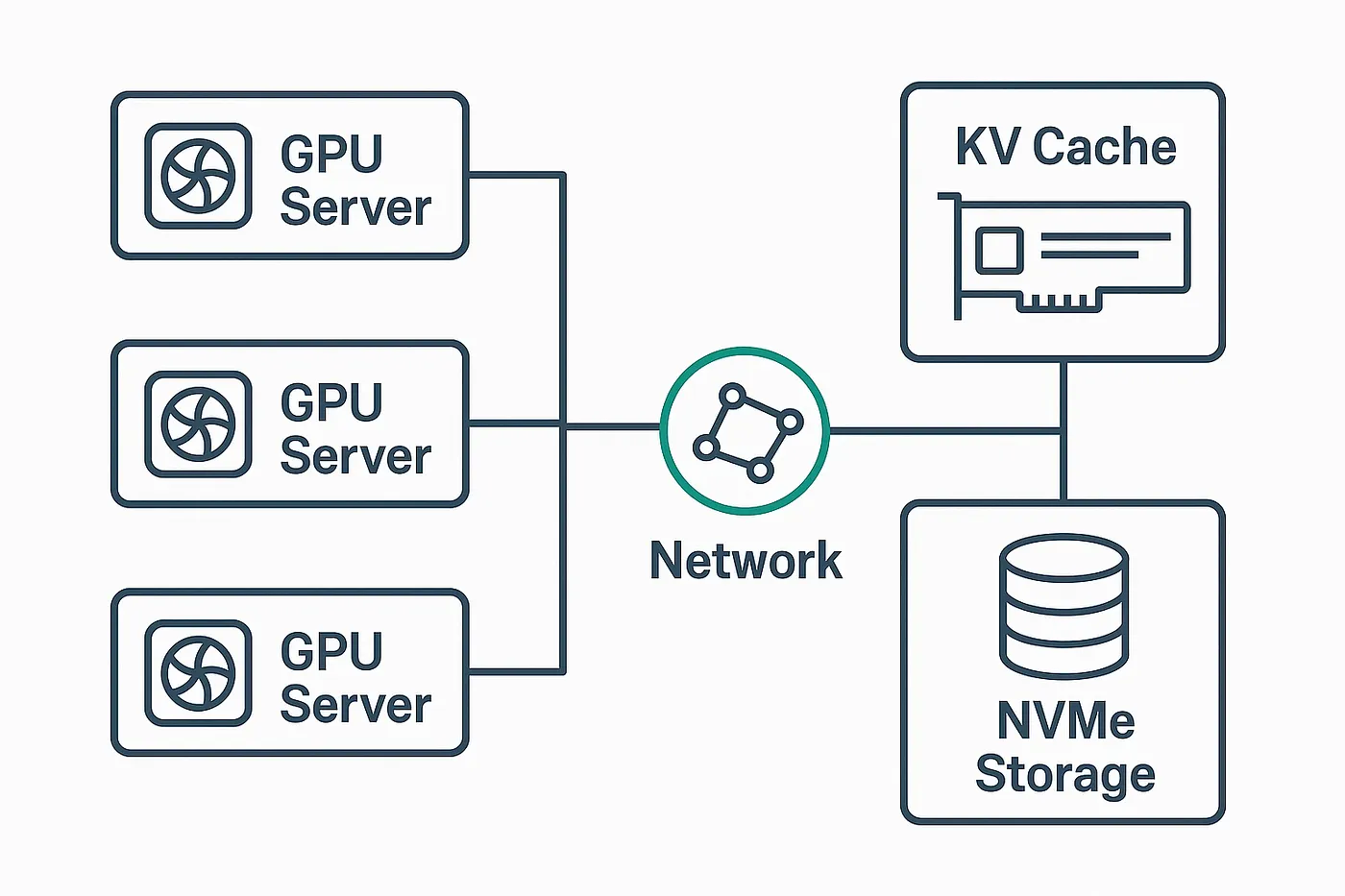
Pliops XDP LightningAI accelerator card (PCIe add-in). This ASIC-powered card, combined with NVMe storage, forms a fast KV cache tier that augments a GPU server's memory.
Integration with the GPU Server
There are two ways to deploy the Pliops solution: either as a local NVMe tier inside the GPU server itself, or as a remote NVMe-backed storage node accessed over the network. We went with the networked setup — it lets multiple GPU servers share the same cache, which is great when users are working with similar inputs (like prompts grounded in the same codebase). This design allows us to scale GPU capacity horizontally while keeping KV reuse high across sessions and machines — all without requiring massive costly VRAM on each individual GPU.
Realistic Multi-Turn Benchmarking
In my previous article on LLM inference, I complained about the general lack of realistic benchmarks for LLM workloads. Thankfully, for the considered use case, there's a proper one available — designed to simulate multi-client, multi-turn chat behavior with an emphasis on cache reuse. Which means I don't have to build one myself (thank God — it's tedious).
At the time of writing, the benchmark hasn't yet been merged into vLLM. It is available in this PR (tracking ticket).
This new benchmark was explicitly created to:
- Accurately simulate multi-turn conversations with persistent history.
- Evaluate KV cache offloading and reuse in environments where cache eviction is likely.
- Reveal performance bottlenecks under concurrent multi-client usage.
- Measure key metrics like TTFT, TPOT, latency, and throughput.
Benchmark Features
1. Conversation Input and Generation
The tool accepts ShareGPT-style JSON datasets or generates synthetic conversations with detailed controls over:
- Number of turns
- Input/output token counts
- Prefix tokens (shared or unique)
- Distributions (uniform, lognormal, constant)
2. Multi-Process Client Simulation
- A configurable number of client processes are launched ( — num-clients)
- All conversation inputs are loaded into a central Task queue.
- Each client manages a defined number of active conversations ( — max-active-conversations)
- Clients select and process conversations in a round-robin or random fashion
3. Simulating Real-World Delays
By alternating between multiple active conversations, each client introduces natural delays between turns. This mimics users pausing mid-conversation and highlights how well cache eviction and retrieval strategies perform under these conditions.
4. Request Execution
Every request includes the entire chat history up to that turn and is sent using the OpenAI-compatible REST API. The benchmark supports both streaming and non-streaming modes.
5. Warm-Up Phase
An optional warm-up step ( — warmup-step) sends the first turn of each conversation in advance to reduce cold-start noise in measurements.
6. Result Collection and Analysis
Results from all clients are fed into a central Result queue, capturing:
- TTFT (Time to First Token)
- TPOT (Time Per Output Token)
- End-to-End Latency
- Requests/sec
7. Diagrammatic Representation
The following diagram illustrates how the benchmark orchestrates multiple client processes, the conversation pool, metrics, and vLLM server interactions:

Example command to run the benchmark:
export MODEL_NAME=/models/meta-llama/Meta-Llama-3.1-8B-Instruct/
python benchmark_serving_multi_turn.py --model $MODEL_NAME \
--input-file generate_multi_turn.json \
--num-clients 2 --max-active-conversations 6
LightningAI vs. Vanilla vLLM: Performance Impact
So… does this actually help, or is it just another fancy hardware detour?
To find out, we compared a basic LLM setup (GPU running solo, no external KV magic) with our upgraded Frankenstein rig that offloads KV cache over the network.
We focused on three things:
- Time-to-First-Token (TTFT): How fast the model starts talking — basically, how long your user stares at a blinking cursor.
- Requests per Second (RPS): How many users you can keep happy at once.
- Time Per Output Token (TPOT): A rough measure of how fast you're cranking out responses once generation starts.
We're seeing a solid 2× to 4× boost in how many requests per second the system can handle — huge win. The same applies to throughput, and all this is achieved without any degradation in latency. If you're going to nitpick (and of course you are, aren't you?), it'd be great to see a side-by-side with pure VRAM-based and DRAM-based caching, just to show exactly when that starts falling apart — like how many users or how long a convo it takes before things crumble. Still, the upside of having what's basically an infinite, shared, long-term cache is pretty obvious — especially when you're running multiple GPUs and dealing with overlapping context.
Alternatives for KV Cache Management
It's worth noting that Pliops is one of several approaches tackling the KV cache challenge — but they're the only ones among hardware vendors brave (or curious) enough to test it with our humble RTX 4090 servers 😄.
Each solution has its trade-offs and ideal use cases:
-
Offloading to CPU Memory (DRAM): Some frameworks — like NVIDIA Dynamo — support spilling KV caches from GPU to system RAM. DRAM is much cheaper and more abundant than VRAM, and latency is better than SSDs. But this solution doesn't scale across servers and doesn't support the use case where you need to share the KV cache across different machines, but it can be a good middle ground.
-
Distributed KV Stores and GPU-Direct Storage: Several vendors have introduced external memory solutions that parallel Pliops' philosophy of a tiered cache, often in the context of NVIDIA's AI ecosystem. For instance, NVIDIA's Dynamo itself is evolving to support a tiered cache hierarchy that ends in network-attached SSDs. A number of storage and data infrastructure companies are aligning with this vision. Products like Hammerspace's "Tier Zero", WEKA's Augmented Memory Grid, and VAST Data's VUA (VAST Undivided Attention) provide a distributed memory or fast SSD layer that supports NVIDIA's GPUDirect storage access for AI workloads. Similarly, software like GridGain's in-memory database can be repurposed to form a distributed shared memory pool across multiple servers. These systems allow an LLM inference cluster to treat a large pool of NVMe-based storage or aggregated RAM as an extension of GPU memory. The trade-off is usually complexity and specialization: some solutions require specific hardware or software stack integration (e.g. using a particular storage appliance or filesystem), and latency can vary depending on network hops and optimization.
Conclusion
Offloading KV cache to fast external storage turned our humble 4090s into surprisingly capable LLM servers.
In a world where GPUs cost more than rent, decoupling memory from compute isn't just smart — it's survival. If you're building GenAI infrastructure on a budget (or just like weird experiments that somehow work), cache offloading might be your new favorite hack.


