Modern GPU Matmul Optimization
The irony of matmul is that it is the simplest kernel to write and the hardest one to optimize. The naive triple loop is three lines; The version that saturates a GPU is a thousand. Optimizing matmul is also a perfect way to learn modern GPU concepts: as the cornerstone of AI, it is the operation that has built a whole ecosystem around itself. And, oh boy, that is some ecosystem! Tensor Memory Accelerator, warp specialization, tensor cores, register tiling, loop factorization, and many more.
This article explains all modern GPU optimizations one at a time. Equipped with these you can write a cuBLAS-equivalent matmul (the implementation here reaches 96% of cuBLAS on a 2048×2048 fp32 matmul, and beats fp16 tensor-core implementation at 105%) and, generally speaking, optimize most of the kernels to the roofline.
We will be using deplodock to lower torch.matmul to CUDA through a
series of optimization passes. The diff for each pass and emitted kernel is printable on demand, which is a nice way
to isolate a specific optimization and understand its mechanism.
git clone https://github.com/cloudrift-ai/deplodock.git
cd deplodock && make setup && source venv/bin/activate
Nearly every number in this post is a 2048×2048×2048 fp32 or fp16 matmul on RTX 5090.
However, certain optimizations require specific conditions, e.g. a skinny matmul shape; they will be called out.
Benchmark setup:
- NVIDIA RTX 5090 (Blackwell,
sm_120, 32 GB) driver 580.159.03- Ubuntu 24.04 (kernel 6.17)
- PyTorch 2.11.0 (
+cu130) linking cuBLAS 13.1.0.3 (cuDNN 9.19)
The reference in every table is PyTorch eager
torch.matmul. On a 2-D contiguous tensor that dispatches straight into cuBLAS, and annsystrace names the exact kernels it runs:fp32: cutlass_80_simt_sgemm_256x128_8x4_nn_align1 fp16: cutlass_80_tensorop_f16_s16816gemm_...128x64_64x3_nn_align8The fp32 path is a CUTLASS SIMT kernel, and the fp16 path is a tensor-core HGEMM. The event-timed eager latency matches the
nsyskernel duration.
Fast Math
Optimizing arithmetic intensity is the easiest optimization to understand: how much math each thread does per byte it loads. The naive kernel does almost none; this part fixes that with register tiling, vectorization, fp16 packing, load interleaving, and finally tensor cores.
I use loop factorization a lot throughout the article to explain various optimization concepts. In a nutshell, you take
a loop and split its iteration space into a few subloops. Each loop is bound to a level of the hardware (a block, a warp, a thread, a register,
a tensor-core atom). For example, you can express a flat loop over 24 elements as three nested loops over its factors (24 = 2·3·4),
and the original index is rebuilt as a mixed-radix sum:
# one flat loop ...
for i in range(24):
body(i)
# ... factored into three tiers (24 = 2 * 3 * 4):
for i0 in range(2): # outer (e.g. block)
for i1 in range(3): # middle (e.g. thread)
for i2 in range(4): # inner (e.g. register)
i = i0 * 12 + i1 * 4 + i2 # rebuild the original index
body(i)
Register Tiling
A naive matmul implementation looks as follows:
for m in 0..64:
for n in 0..64:
Init(acc)
for k in 0..32 reduce:
a = load A[m, k]
b = load B[k, n]
Accum(acc, a*b)
Write(C[m, n], acc)
On a GPU the two output axes factorize first into a block tier and a thread tier. For A[64,32] @ B[32,64]
with a 16×16 thread block, each thread still computes one output cell:
for m_b in 0..4 BLOCK:
for n_b in 0..4 BLOCK:
for m_t in 0..16 THREAD:
for n_t in 0..16 THREAD:
Init(acc)
for k in 0..32 reduce:
a = load A[m_b·16 + m_t, k]
b = load B[k, n_b·16 + n_t]
Accum(acc, a*b)
Write(C[m_b·16 + m_t, n_b·16 + n_t], acc)
That is two global loads per multiply-add, about the worst arithmetic intensity you can get. Register tiling gives
each thread a small FM × FN grid of cells instead, so it loads FM values of A and FN of B once and reuses them
for FM·FN multiply-adds (an outer product in registers). Adding a 2×2 register tier (FM=FN=2) under each thread
makes a block cover 16·2 = 32 cells per axis, so the block grid shrinks from 4×4 to 2×2:
DEPLODOCK_KNOBS="FM=2,FN=2" \
deplodock compile \
-c "torch.matmul(torch.randn(64,32),torch.randn(32,64))" \
--ir tile
for m_b in 0..2 BLOCK:
for n_b in 0..2 BLOCK:
for m_t in 0..16 THREAD:
for n_t in 0..16 THREAD:
for m_r in 0..2 REGISTER: # the 2×2 cell grid
for n_r in 0..2 REGISTER:
Init(acc)
for k in 0..32 reduce:
a = load A[m_b·32 + m_t·2 + m_r, k]
b = load B[k, n_b·32 + n_t·2 + n_r]
Accum(acc, a*b)
Write(C[m_b·32 + m_t·2 + m_r, n_b·32 + n_t·2 + n_r], acc)
BN/BM set how many threads tile the block; FN/FM how many cells each thread owns. Use the following command to see the rewrite pass:
DEPLODOCK_KNOBS="FM=2,FN=2" \
deplodock compile \
-c "torch.matmul(torch.randn(32,32),torch.randn(32,32))" \
--ir tile -vv | awk '/^>>> t:010/,/^<<< t:010/'
-matmul = LoopOp(x1, x0)
- for a0 in 0..32
- for a1 in 0..32
- for a2 in 0..32
- in0 = load x1[a2, a1]
- in1 = load x0[a0, a2]
- v0 = multiply(in0, in1)
- acc0 <- add(acc0, v0)
- matmul[a0, a1] = acc0
+matmul = TileOp(x1, x0)
+ for a0 in 0..2 │
+ for a1 in 0..1 └ grid
+ for a2 in 0..8 │
+ for a3 in 0..32 └ thread
+ for a4 in 0..2 │
+ for a5 in 0..2 └ register
+ if (a1 * 64 + a5 * 32 + a3) < 32:
+ for a6 in 0..32
+ in0 = load x1[a6, a1 * 64 + a5 * 32 + a3]
+ in1 = load x0[a0 * 16 + a2 * 2 + a4, a6]
+ v0 = multiply(in0, in1)
+ acc0 <- add(acc0, v0)
+ matmul[a0 * 16 + a2 * 2 + a4, a1 * 64 + a5 * 32 + a3] = acc0
With deplodock we can compile and run kernels with register tiling and without by configuring the FM and FN knobs.
Here are the commands and the final result:
C="torch.matmul(torch.randn(2048,2048),torch.randn(2048,2048))"
# without register tiling — one output cell per thread
DEPLODOCK_KNOBS="BM=8,BN=32,FM=1,FN=1,BK=32,SPLITK=1,TMA=1,STAGE=11" \
deplodock run -c "$C" --bench
# with register tiling — a 26×4 grid of cells per thread (the full tuned set)
DEPLODOCK_KNOBS="BM=8,BN=32,FM=26,FN=4,BK=32,SPLITK=1,TMA=1,STAGE=11" \
deplodock run -c "$C" --bench
A 5.2× speed-up: the inner loop went from load-bound to FMA-bound. This is the toggle measured against the full
tuned set, so the 275 µs "on" number already carries all the optimizations; what register
tiling itself buys, with everything else held on, is that 5.2×. It is the biggest single lever between the naive kernel
and a competitive one.
Shrinking the per-thread tile automatically launches proportionally more blocks: the FM=1,FN=1
kernel fans out to 16384 CTAs at 100% occupancy, the 26×4 tile to just 160 CTAs at 17%. The coarse tile wins by
5× despite running at a sixth of the occupancy, which is the counter-intuitive part of this optimization.
# no register tiling
Backend Latency (us) vs Eager
-----------------------------------------
Eager PyTorch 275 1.00x
Deplodock 1404 0.20x
Kernel us % grid block smem regs occ
-------------------------------------------------------------------------
k_matmul_bed174 1404.5 100.0% 16384 256 20.0K 47 67%
TOTAL 1404.5
# register tiling
Backend Latency (us) vs Eager
----------------------------------------
Eager PyTorch 262 1.00x
Deplodock 275 0.95x
Kernel us % grid block smem regs occ
-------------------------------------------------------------------------
k_matmul_bed174 275.5 100.0% 160 256 84.0K 255 17%
TOTAL 275.5
Vectorized Loads (LDS / LDG.128)
Specialized. Coalesced memory access is one of the classic hand-written-kernel wins. However, modern NVCC auto-vectorizes the body. Toggling vectorization on and off measures 0% difference at every
-Olevel — and it stays zero even on a deliberately load-bound tile (FM=1, FN=4); nvcc's back-end recoalesces the runs of consecutive scalar loads into wideLDS.128/LDG.128transactions itself. The only flag that makes the pass change the machine code is -Xptxas -O0, the one level that disables the coalescer. Nvcc does fail to coalesce on less regular kernels (unprovable alignment, gapped strides), so it is still worth keeping the optimization in mind.
A run of consecutive loads from the same buffer should be one wide memory transaction, not N narrow ones. One
LDG.128 moves four floats in the time of one LDG.32; LDG.64 moves two. The vectorizer folds adjacent scalar loads into one vector load:
DEPLODOCK_KNOBS="FM=2,FN=2" \
deplodock compile \
-c "torch.matmul(torch.randn(32,32),torch.randn(32,32))" \
--ir kernel -vv | awk '/^>>> k:050/,/^<<< k:050/'
for a5 in 0..16
- in0 = load x1[((a4 * 16) + a5), ((a1 * 32) + (a3 * 2))]
- in1 = load x1[((a4 * 16) + a5), (((a1 * 32) + (a3 * 2)) + 1)]
+ in0, in1 = load x1[((a4 * 16) + a5), ((a1 * 32) + (a3 * 2))]
In the emitted CUDA the two scalar reads collapse into one 64-bit transaction (float4 at wider tiles):
// before: two LDG.32
float in0 = x1[(a4*16+a5)*32 + (a1*32+a3*2)];
float in1 = x1[(a4*16+a5)*32 + (a1*32+a3*2) + 1];
// after: one LDG.64
float2 _v = *reinterpret_cast<const float2*>(&x1[(a4*16+a5)*32 + (a1*32+a3*2)]);
float in0 = _v.x, in1 = _v.y;
Load Interleaving
Specialized. Same as with coalesced memory access, load/compute interleaving is a wash at every deployable
-Olevel. Only -Xptxas -O0 preserves the source order.
Register tiling unrolls the cell grid into a flat block: a handful of loads, then all the FMAs. At FM=FN=8 that is a
dozen smem loads followed by 64 multiply-adds, and ptxas has to schedule those loads against the FMAs across the whole
window. Handwritten SGEMM templates instead emit each A-load right before the FMAs that consume it, so the load sits
next to its use. The INTERLEAVE_LOADS pass does the same, sinking each load to just before its first consumer:
DEPLODOCK_KNOBS="BM=16,BN=16,FM=4,FN=4,BK=16,STAGE=11,INTERLEAVE_LOADS=0" \
deplodock compile \
-c "torch.matmul(torch.randn(256,256),torch.randn(256,256))" \
--ir cuda --target sm_70
// INTERLEAVE_LOADS=0 — every load hoisted, then every FMA
float in4 = x0_smem[...]; float in5 = x0_smem[...]; float in6 = ...; float in7 = ...;
// FMAs all after
float v0 = in0*in4; float v1 = in0*in5; float v2 = in0*in6; ...
// INTERLEAVE_LOADS=1 (default) — each load sunk next to its first use
float in4 = x0_smem[...]; float v0 = in0*in4;
float in5 = x0_smem[...]; float v1 = in0*in5;
float in6 = x0_smem[...]; float v2 = in0*in6;
Tensor Cores
Tensor cores are the ultimate GPU compute flex. Tensor cores compute a whole 16×8 output tile
per warp with a single matrix instruction. However, tensor cores are limited to lower precision math (NVFP4, FP8, FP16),
so for regular scientific computing we're stuck with regular FMA.
Usage of tensor cores requires the deepest loop nest factorization in the post: the output axis grows a
fourth tier, and the innermost cell is no longer a scalar register but a hardware atom: the indivisible m16n8k16
mma.sync tile (CUTLASS's term; it is what the ATOM_KIND knob selects):
for m_b in 0..M/(WM·FM·16) BLOCK:
for n_b in 0..N/(WN·FN·8) BLOCK:
for m_w in 0..WM WARP:
for n_w in 0..WN WARP:
for m_r in 0..FM REGISTER:
for n_r in 0..FN REGISTER:
# 16×8 fp32 atom accumulator
MmaInit(acc)
for k_o in 0..K/16 SERIAL_OUTER:
a = MmaLoad(A_smem[m_w·FM·16+m_r·16, k_o·16]) # 16×16 A
b = MmaLoad(B_smem[k_o·16, n_w·FN·8+n_r·8]) # 16×8 B
# one mma.sync = 16×8×16
MmaSync(acc, a, b)
MmaStore(C[m_w·FM·16 + m_r·16, n_w·FN·8 + n_r·8], acc)
In CUDA the per-thread FMA loop is gone. ldmatrix cooperatively loads the operand fragments and mma.sync runs the
16×8×16 multiply, fp16 in → fp32 out (the accumulator is fp32, the same precision as cuBLAS's HGEMM):
// the m16n8k16 atom is a single PTX instruction — fp16 x fp16 -> fp32
__device__ __forceinline__
void mma_m16n8k16(float d[4],
const unsigned a[4],
const unsigned b[2],
const float c[4]) {
asm volatile(
"mma.sync.aligned.m16n8k16.row.col.f32.f16.f16.f32 "
"{%0, %1, %2, %3}, {%4, %5, %6, %7}, {%8, %9}, {%10, %11, %12, %13};\n"
: "=f"(d[0]), "=f"(d[1]), "=f"(d[2]), "=f"(d[3]) // D: 16x8 fp32 out
: "r"(a[0]), "r"(a[1]), "r"(a[2]), "r"(a[3]), // A: 16x16 fp16 (4 regs)
"r"(b[0]), "r"(b[1]), // B: 16x8 fp16 (2 regs)
"f"(c[0]), "f"(c[1]), "f"(c[2]), "f"(c[3])); // C: 16x8 fp32 accum
}
// fp32 accumulators — 4 regs per m16n8 atom, spread across the warp's 32 lanes
float acc[4] = {0, 0, 0, 0};
for (int k = 0; k < K; k += 16) { // one step = a 16×8×16 atom
unsigned a_frag[4], b_frag[2]; // packed half operands
ldmatrix_x4(a_frag, &A_smem[m_w*16][k]);
ldmatrix_x2_trans(b_frag, &B_smem[k][n_w*8]);
// tensor-core multiply-accumulate (acc is both the C input and the D output)
mma_m16n8k16(acc, a_frag, b_frag, acc);
}
// store the 4 fp32 lanes back to C
I use
mma.sync(thes16816mma.sync.aligned.m16n8k16+ldmatrix) rather than the WMMA API. Inline PTX is less readable, but it has proven to be faster.
Tensor core kernel runs at lower precision (fp16 multiplications and fp32 accumulation), but it is almost three times faster: 94us vs 262us.
Data Movement
A fast inner loop is useless if it starves. This part is about moving inputs tiles from global memory to the compute units, then overlapping each tile's load with the previous tile's math.
Here is the illustration of the load/compute overlap that we are trying to achieve:
Shared-Memory Staging
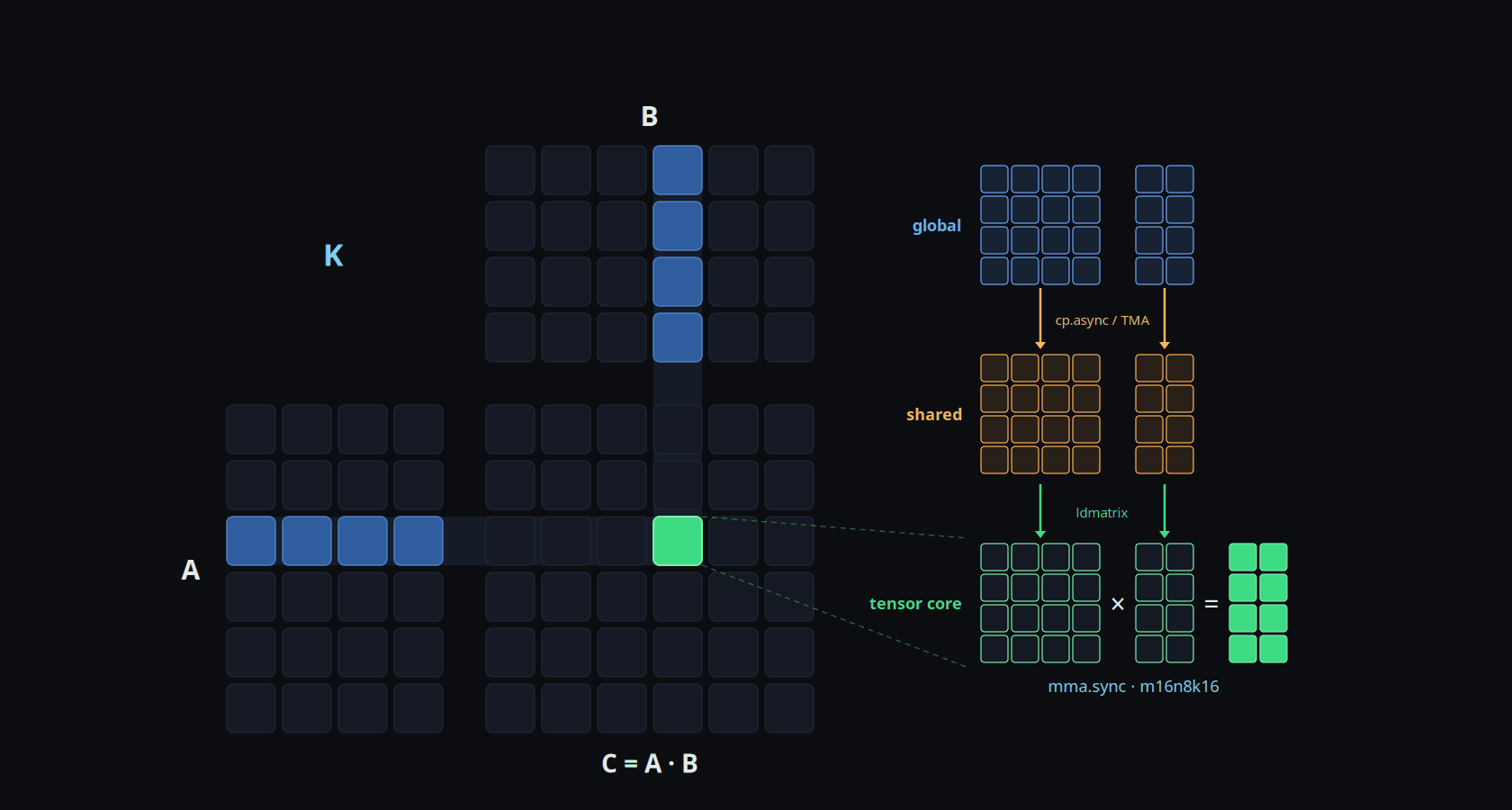
Register tiling reuses data within a thread. Neighboring threads in a block want overlapping rows of A and columns of
B, and fetching them independently wastes bandwidth. Staging loads a slab of A and B into shared memory once,
cooperatively, and every thread reads its operands from there. This is where the K reduction splits into BK-sized
slabs: an outer loop over chunks (SERIAL_OUTER, a4 below) wrapping an inner reduce over one slab (STAGE_INNER,
a5). The inner reduce gets wrapped in a shared-memory bundle that loads the slab before the threads consume it.
Dropping the register tier (FM=FN=1) for clarity, the factorized nest is:
for m_b in 0..4 BLOCK:
for n_b in 0..4 BLOCK:
for m_t in 0..16 THREAD:
for n_t in 0..16 THREAD:
Init(acc)
for k_o in 0..4 SERIAL_OUTER: # K split into 16 chunks
bundle sync: # cooperative fill
A_smem ← A[m_b·16 + ·, k_o·16 + ·] # one 16×16 slab of A
B_smem ← B[k_o·16 + ·, n_b·16 + ·] # one 16×16 slab of B
for k_i in 0..16 STAGE_INNER reduce:
a = load A_smem[m_t, k_i] # read from shared
b = load B_smem[k_i, n_t]
Accum(acc, a*b)
Write(C[m_b·16 + m_t, n_b·16 + n_t], acc)
In Deplodock Tile IR the bundle sync defines a synchronized smem pipeline. It will take care of shared memory declaration,
cooperative fill, and thread synchronization. It is similar in spirit to CuTe API where you build the smem and gmem tiles
from layouts and issue one cooperative copy:
// CuTe (CUTLASS): assemble the staged copy from tensors + a tiled copy
Tensor sA = make_tensor(make_smem_ptr(smemA), SmemLayoutA{}); // the smem slab
Tensor gA = local_tile(mA, BlkShape{}, blk_coord); // the gmem slab
// each thread copies its slice
auto thr = tiled_copy.get_slice(threadIdx.x);
copy(thr.partition_S(gA), thr.partition_D(sA));
__syncthreads();
The diff logger shows the same rewrite on one bundle:
DEPLODOCK_KNOBS="STAGE=11" \
deplodock compile \
-c "torch.matmul(torch.randn(64,64),torch.randn(64,64))" \
--ir tile -vv --target sm_70 \
| awk '/^>>> t:020/,/^<<< t:020/'
for a4 in 0..4
- for a5 in 0..16
- in0 = load x1[((a4 * 16) + a5), ((a1 * 16) + a3)]
- in1 = load x0[((a0 * 16) + a2), ((a4 * 16) + a5)]
+ bundle sync:
+ shared x1_smem[a5:16, a3:16] = x1[(a4 * 16) + a5, (a1 * 16) + a3]
+ shared x0_smem[a2:16, a5:16] = x0[(a0 * 16) + a2, (a4 * 16) + a5]
+ for a5 in 0..16
+ in0 = load x1_smem[a5, a3] ← read from shared, not global
+ in1 = load x0_smem[a2, a5]
In CUDA the bundle becomes a __shared__ slab, a cooperative load, a __syncthreads(), and a reduce that reads from
shared instead of global. Here is the whole (small) kernel for a 2×2 register tile:
DEPLODOCK_KNOBS="BM=16,BN=16,FM=2,FN=2,BK=16,STAGE=11,TMA=0,ASYNC_COPY=0" \
deplodock compile \
-c "torch.matmul(torch.randn(128,128),torch.randn(128,128))" \
--ir cuda --target sm_70
// reflowed: flat smem index renamed (x1_smem_flat → f), swizzle preamble elided
extern "C" __global__ __launch_bounds__(256)
void k_matmul(const float* x1, const float* x0, float* matmul) {
// (+ CTA-swizzle preamble)
int a0 = /*block row*/, a1 = /*block col*/;
int a2 = threadIdx.x / 16, a3 = threadIdx.x % 16;
__shared__ float x1_smem[1024]; // 2 buffers x 16x32 (B slab)
__shared__ float x0_smem[1088]; // 2 buffers x 16x34 (A slab, +1 pad)
float acc0=0, acc1=0, acc2=0, acc3=0; // the 2x2 register tile
// K in BK=16 chunks
#pragma unroll
for (int a4 = 0; a4 < 8; a4++) {
// cooperative load: global -> shared
for (int f = a2*16+a3; f < 512; f += 256)
x1_smem[a4%2*512 + f/32*32 + f/2%16*2 + f%2] =
x1[(a4*16 + f/32)*128 + (a1*32 + f/2%16*2 + f%2)];
for (int f = a2*16+a3; f < 512; f += 256)
x0_smem[a4%2*544 + f/32*34 + f/16%2*17 + f%16] =
x0[(a0*32 + f/32*2 + f/16%2)*128 + (a4*16 + f%16)];
// wait for the slab to fill
__syncthreads();
// the BK reduce, from smem
for (int a5 = 0; a5 < 16; a5++) {
float2 b = *(const float2*)&x1_smem[a4%2*512 + a5*32 + a3*2];
float a_0 = x0_smem[a4%2*544 + a2*34 + a5];
float a_1 = x0_smem[a4%2*544 + a2*34 + 17 + a5];
// the 2x2 outer product
acc0 += b.x*a_0; acc1 += b.x*a_1;
acc2 += b.y*a_0; acc3 += b.y*a_1;
}
}
matmul[(a0*32 + a2*2 )*128 + a1*32 + a3*2 ] = acc0;
matmul[(a0*32 + a2*2 + 1)*128 + a1*32 + a3*2 ] = acc1;
matmul[(a0*32 + a2*2 )*128 + a1*32 + a3*2 + 1] = acc2;
matmul[(a0*32 + a2*2 + 1)*128 + a1*32 + a3*2 + 1] = acc3;
}
Double-Buffering
The staged loop has a structural stall: load slab, sync, compute, repeat. Each iteration waits on its load. The fix is
to start loading slab k+1 while computing slab k. The bundle policy flips from sync to buffered, and the smem reads gain a phase index:
DEPLODOCK_KNOBS="BM=16,BN=16,FM=1,FN=1,BK=16,SPLITK=1,STAGE=11" \
deplodock compile \
-c "torch.matmul(torch.randn(64,64),torch.randn(64,64))" \
--ir tile -vv --target sm_70 \
| awk '/^>>> t:040/,/^<<< t:040/'
-bundle sync:
+bundle buffered[2@(a4 % 2)]: ← two buffers, alternating
shared x1_smem[...] = x1[...]
for a5 in 0..16
- in0 = load x1_smem[a5, a3]
+ in0 = load x1_smem[(a4 % 2), a5, a3] ← phase index
Async-Copy and TMA
On sm_80+ the synchronous copy becomes an async copy (cp.async): the load goes global→shared directly, skipping
registers, and the warp issues a commit/wait instead of blocking:
DEPLODOCK_KNOBS="BM=16,BN=16,FM=1,FN=1,BK=16,SPLITK=1,STAGE=11" \
deplodock compile \
-c "torch.matmul(torch.randn(64,64),torch.randn(64,64))" \
--ir tile -vv --target sm_80 \
| awk '/^>>> t:060/,/^<<< t:060/'
-bundle buffered[2@(a4 % 2)]:
+bundle async[2@(a4 % 2)]:
In CUDA it will translate to cp.async PTX:
asm volatile("cp.async.ca.shared.global [%0], [%1], 4;\n" :: "r"(smem_addr),
"l"(&x1[...]));
asm volatile("cp.async.commit_group;\n");
asm volatile("cp.async.wait_group 1;\n"); // keep the most recent group in flight
On sm_90+ the same staged loop lowers to TMA: instead of a per-element cp.async loop, a single
hardware descriptor copies the whole 2-D tile and signals an mbarrier. The bundle flips buffered → tma (this needs a
larger TMA-eligible tile, so it is shown on the tuned 26×4 one rather than the toy FM=1 tile above):
DEPLODOCK_KNOBS="BM=8,BN=32,FM=26,FN=4,BK=32,SPLITK=1,STAGE=11,TMA=1" \
deplodock compile \
-c "torch.matmul(torch.randn(2048,2048),torch.randn(2048,2048))" \
--ir tile -vv --target sm_90 \
| awk '/^>>> t:050/,/^<<< t:050/'
-bundle buffered[2@(a6 % 2)]:
+bundle tma[2@(a6 % 2)]:
In CUDA the cooperative cp.async loop collapses to a single descriptor copy guarded by an mbarrier (the
mbarrier_* / cp_async_bulk_tensor_2d calls are thin PTX wrappers):
// producer: one TMA copies the whole slab, signalling the mbarrier when ready
mbarrier_arrive_expect_tx(&tma_mbar[slot], 16384);
cp_async_bulk_tensor_2d(&x1_smem[slot], x1_smem_desc, a1*128, 0, &tma_mbar[slot]);
// consumer: wait on the barrier's parity bit, then read the slab from smem
mbarrier_wait_parity(&tma_mbar[slot], phase);
Software Pipelining
cp.async and TMA let a load fly without blocking, but the staged loop still issues one chunk and waits for it before
computing — only one tile is ever in flight. Software pipelining keeps N-1 tiles in flight: issue chunk k+1 while
the math on chunk k runs. The compiler peels the K-outer loop into a prologue that issues the first chunk, a
main loop that issues k+1, waits for k to land, then consumes k, and an epilogue that drains the last
chunk. With two buffers that is the classic double-buffer schedule; with more, the CUTLASS multistage shape.
DEPLODOCK_KNOBS="BM=16,BN=16,FM=1,FN=1,BK=16,STAGE=11,TMA=0" \
deplodock compile \
-c "torch.matmul(torch.randn(128,128),torch.randn(128,128))" \
--ir tile -vv \
| awk '/^>>> t:080/,/^<<< t:080/'
-for a5 in 0..2
- bundle async[2@a5]:
- shared x1_smem[...] = x1[...]
- for a6 in 0..16: acc0 <- in0*in1
+bundle async[2@0 depth=2]: ← prologue: issue chunk 0 (load only)
+ shared x1_smem[...] = x1[...]
+for a6 in 0..1: ← main loop
+ bundle async[2@(a6+1) depth=2]: ← issue chunk a6+1 (the next one)
+ shared x1_smem[...] = x1[...]
+ AsyncWait(keep=1) ← until only 1 copy is in flight → ready
+ for a5 in 0..16: acc0 <- in0*in1 ← consume chunk a6
+ AsyncWait(keep=1)
+AsyncWait(keep=0) ← epilogue: drain and consume the last
+for a5 in 0..16: acc0 <- in0*in1
The pipeline depth equals the buffer count: two buffers give the prologue/main/epilogue above; bumping it issues more
outstanding copies, so a deeper memory latency stays hidden under compute. The PIPELINE_STAGES knob (default on)
controls it.
Warp Specialization
cp.async and TMA still interleave loads and math in the same warp. On sm_90+ you can go further and specialize
warps: a producer warp does nothing but issue TMA copies, while consumer warps do nothing but compute, decoupled
through a shared ring buffer.
This re-factorizes the block: output cells bind to warps instead of threads (a WARP tier replaces THREAD), and the
block's warps split into one producer and WM·WN consumers that hand off through a shared ring buffer:
for m_b in 0..M/(WM·FM·16) BLOCK:
for n_b in 0..N/(WN·FN·16) BLOCK:
warp_specialize(ring=2):
producer warp: # 1 warp — loads only
for k_o in 0..K/BK SERIAL_OUTER:
TmaLoad(A_smem[k_o%2], B_smem[k_o%2]) # issue next tile
Arrive(full[k_o%2])
consumer warps: # WM·WN warps — compute only
for m_w in 0..WM WARP:
for n_w in 0..WN WARP:
Init(acc)
for k_o in 0..K/BK SERIAL_OUTER:
Wait(full[k_o%2])
for k_i in 0..BK STAGE_INNER reduce:
a = A_smem[k_o%2][m_w·16 + k_i]
b = B_smem[k_o%2][k_i, n_w·16]
Accum(acc, a * b)
Arrive(empty[k_o%2])
Write(C[m_w·16, n_w·16], acc)
The compiler's diff shows that exact split: the thread tier becomes a warp tier and the body forks into
producer: / consumer: arms:
DEPLODOCK_KNOBS="BM=64,BN=64,FM=4,FN=4,BK=32,WARP_SPECIALIZE=1" \
deplodock compile \
-c "torch.matmul(torch.randn(512,512),torch.randn(512,512))" \
--ir tile -vv --target sm_120 \
| awk '/^>>> t:085/,/^<<< t:085/'
-for a3 in 0..256 └ thread
- for a4 in 0..8; for a5 in 0..2 └ register
+for a3 in 0..9 └ warp
+ warp_specialize(ring=2, n_prod=32):
+ producer: ← issues TMA copies only
+ bundle tma[2@0 depth=2]:
+ shared x0_smem[...] = x0[...]
+ consumer: ← computes only
+ AsyncWait(...); acc0 <- add(acc0, multiply(in0, in1))
In CUDA the warps branch on their id and synchronize through an mbarrier ring: the producer issues the TMA and
signals bytes-in-flight, the consumers wait on the parity bit, compute, and signal the slot free:
int warp = threadIdx.x / 32;
if (warp == PRODUCER_WARP) { // producer: feed the ring
mbarrier_arrive_expect_tx(&full[slot], TILE_BYTES);
cp_async_bulk_tensor(&smem[slot], tma_desc, ...);
} else { // consumers: drain + compute
mbarrier_wait_parity(&full[slot], phase);
mma_m16n8k16(acc, a_frag, b_frag); // (or scalar FMAs)
mbarrier_arrive(&empty[slot]);
}
This is the structure modern Hopper and Blackwell GEMMs are built on, and on the fp16 tensor-core path it is the optimization
that finally pushes deplodock past cuBLAS: the producer warp keeps the TMA ring full so the consumer warps run an
uninterrupted mma.sync chain with no load stalls between tiles. It is still the most situational organization, it only pays
for deep pipelines with enough warps to spare a producer, but on the fp16 GEMM it earns its keep.
Staging Benchmarks
The benchmark below compares different transports on a 2048x2048 matmul with a golden knob set: gmem direct, staging, cp.async, TMA, pipelining:
BASE="BM=8,BN=32,FM=26,FN=4,BK=32,SPLITK=1"
C="torch.matmul(torch.randn(2048,2048),torch.randn(2048,2048))"
# gmem direct
DEPLODOCK_KNOBS="$BASE,STAGE=00" \
deplodock run -c "$C" --bench
# staged (sync)
DEPLODOCK_KNOBS="$BASE,STAGE=11,TMA=0,ASYNC_COPY=0,PIPELINE_STAGES=0" \
deplodock run -c "$C" --bench
# cp.async
DEPLODOCK_KNOBS="$BASE,STAGE=11,TMA=0,PIPELINE_STAGES=0" \
deplodock run -c "$C" --bench
# TMA
DEPLODOCK_KNOBS="$BASE,STAGE=11,TMA=1,PIPELINE_STAGES=0" \
deplodock run -c "$C" --bench
# + pipelining
DEPLODOCK_KNOBS="$BASE,STAGE=11,TMA=1" \
deplodock run -c "$C" --bench
Pipelining is the optimization that pays on both transports, not only TMA: flip PIPELINE_STAGES to isolate it:
Warp specialization is the fp16 endgame. With the golden fp16 knob set — a four-warp consumer block (WM=1,WN=4,FM=4,FN=2)
fed by one dedicated TMA producer warp over a depth-2 ring (BUFFER_COUNT=2,WARP_SPECIALIZE=1), the mma.sync
kernel beats cuBLAS's HGEMM outright:
M="torch.randn(2048,2048,dtype=torch.float16,device='cuda')"
C="a=$M;b=$M;torch.matmul(a,b)"
K="TMA=1,ATOM_KIND=mma_m16n8k16_f16,BK=2"
# mma (no WS) — the bare tensor-core kernel
DEPLODOCK_KNOBS="$K,WM=2,WN=4,FM=4,FN=4,BUFFER_COUNT=3" \
deplodock run --bench --code "$C"
# warp-specialized — one TMA producer warp feeds four mma consumer warps
DEPLODOCK_KNOBS="$K,WM=1,WN=4,FM=4,FN=2,BUFFER_COUNT=2,WARP_SPECIALIZE=1,SPLITK=1" \
deplodock run --bench --code "$C"
You might be wondering how it is possible to beat cuBLAS on a mainstream fp16 HGEMM. It turns out that cuBLAS is using an old Ampere-era cp.async-based kernel. Using tensor cores, but no TMA, no warp specialization. NVIDIA is constantly improving cuBLAS, so they could have fixed the performance in the newer version, but right now, nor stable, nor nightly PyTorch are beating the fp16 kernel outlined here.
Bank Conflicts
Shared memory is only fast when a warp's 32 lanes hit 32 distinct banks; when they collide, the access serializes. Optimizations in this section keep loads conflict free.
Swizzle Modes and Broadcasting
When using TMA, you will typically get a conflict-free version automatically because of these two features:
Broadcasting. When every lane of a warp reads the same shared-memory address, the hardware serves it in one broadcast cycle. A load that fans one value across the whole warp is conflict-free whatever the layout.
Swizzle modes. When lanes read different addresses, the fix is to permute the address bits so consecutive rows
land in different banks — an XOR of the column index against the row. A TMA descriptor encodes exactly this
(CU_TENSOR_MAP_SWIZZLE_32B / 64B / 128B): the bulk copy lands the tile into shared memory already swizzled, and the
matching ldmatrix reads the fragments back conflict-free in hardware (CUTLASS smem layouts are built on the same XOR
trick).
Shared-Memory Padding
Specialized. Padding does nothing for the tuned 2048³ TMA kernel — TMA swizzles the slab in hardware, so there is no conflict to break. This section drops to the
cp.asynctransport, where the conflict it fixes is real.
Shared memory is 32 banks wide; if a warp's threads stride such that they all hit the same bank, the access serializes
32-way. Padding one shared dimension by one element shifts each row into a different bank. The transform adds a pad to
the staged buffer:
DEPLODOCK_KNOBS="FM=2,FN=2,STAGE=11,PAD_SMEM=1" \
deplodock compile \
-c "torch.matmul(torch.randn(256,256),torch.randn(256,256))" \
--ir tile -vv --target sm_70 \
| awk '/^>>> t:070/,/^<<< t:070/'
shared x1_smem[a7:16, a3:16, a5:2] = x1[...]
-shared x0_smem[a2:16, a4:2, a7:16] = x0[...]
+shared x0_smem[a2:16, a4:2, a7:16] = x0[...] pad=(0, 0, 1)
In CUDA the pad is one extra column on the inner stride, so successive rows start in a different bank:
// unpadded: rows aligned → same-bank column collides across the warp
// row stride 16
__shared__ float x0_smem[16 * 16];
// padded: +1 column shifts each row's banks
// row stride 17 → row r starts at bank (17·r) % 32
__shared__ float x0_smem[16 * (16 + 1)];
A conflict fires only when threads of one warp target different addresses on the same bank. If several lanes read the same address, the bank broadcasts it in one cycle, free. So the punch-card colors cells by address, not by lane: a column of identically-colored cells on one bank is a broadcast (free); different colors stacked on one bank are distinct addresses contending, which costs one cycle per distinct address.
The visualizer below shows a weight slab in a Linear matmul, unpadded (left) versus +1-padded (right). Top half: the warp's 32 lanes plotted by target
bank, where stacked colors mean conflicts. Bottom half: the smem slab colored by bank. The pad shifts each row into a
fresh bank, so the stacked-color columns on the left spread out on the right:
Our tuned TMA tile does not have conflicts, so there is nothing for PAD_SMEM to fix and it moves nothing. To reproduce some conflicts
I will use the cp.async transport (TMA=0). The 26×4 tile reads its B strip as a float4, and at stride-128 the lanes collide four ways on the shared-memory banks:
DEPLODOCK_KNOBS="BM=8,BN=32,FM=26,FN=4,BK=32,SPLITK=1,STAGE=11,TMA=0,PIPELINE_STAGES=0,PAD_SMEM=0" \
deplodock run -c "torch.matmul(torch.randn(2048,2048),torch.randn(2048,2048))" --bench
A 3.7× win. The +1 pad shifts the slab's row stride from 128 to 160, so each row starts in a fresh bank and the
four-way collision disappears (the generated read drops from a conflicted float4 to a conflict-free scalar load — the
pad breaks 16-byte alignment, and a conflict-free scalar beats a serialized vector four times over).
Grid Scheduling
Everything so far was used to tune a single block. This part focuses on the order the blocks are scheduled, and how many blocks the problem is cut into.
CTA Swizzle
Specialized. Swizzle is a wash on the compute-bound 2048³ kernel: L2 reuse never reaches the critical path. This section scales up to an L2-bound
8192³with a low-intensity tile to show where it pays.
Two thread-blocks computing neighboring output tiles share an input row- or column-tile. Walking the grid row-major launches those neighbors far apart in time, so the shared tile is evicted from L2 before the second block wants it. Swizzling the block index so it walks in groups keeps the tile hot. It is a one-token change to the grid:
deplodock compile \
-c "torch.matmul(torch.randn(256,256),torch.randn(256,256))" \
--ir tile -vv \
| awk '/^>>> t:025/,/^<<< t:025/'
for a0 in 0..8
- for a1 in 0..8 └ grid
+ for a1 in 0..8 └ grid swizzle_M=8
In CUDA the grid stays 1-D and a small preamble remaps blockIdx.x so consecutive blocks walk GROUP_M tiles down M
before stepping N:
int bid = blockIdx.x;
int gsz = GROUP_M * num_n; // blocks in one M-group × all of N
int gid = bid / gsz;
int first_m = gid * GROUP_M;
int gsize_m = min(GROUP_M, num_m - first_m);
int m_block = first_m + (bid % gsz) % gsize_m; // walk down M first
int n_block = (bid % gsz) / gsize_m; // then across N
On the tuned 2048³ kernel this changes nothing: that kernel is compute-bound, so L2 hit rate never reaches the critical
path. To see swizzle pay, you need an L2-bound kernel — a large square so the column panels overflow L2, with a
low-intensity tile (FM=FN=4) so bandwidth, not the FMA units, is the bottleneck. At 8192³ that is the case:
DEPLODOCK_KNOBS="BM=16,BN=16,FM=4,FN=4,BK=32,SPLITK=1,STAGE=11,TMA=1,GROUP_M=1" \
deplodock run -c "torch.matmul(torch.randn(8192,8192),torch.randn(8192,8192))" --bench
A modest 5% win. Swizzle changes which SM touches which tile, so it only ever recovers L2 traffic the row-major walk wasted, and the RTX 5090's
large L2 already holds most of the working set even at 8192³. On a card with a smaller L2, or a shape with wider
panels, the same GROUP_M flip is worth more.
Split-K
Specialized. Split-K is a loss on the 2048³ square — the grid already fills the GPU. This section switches to a skinny
128×128×16384matrix, the shape it is built for.
When M and N are small but K is huge, the output grid is tiny. A 128×128 output tiled at 32×32 is 16 blocks; on a
170-SM GPU that leaves 90% of the machine idle while each block grinds an enormous K loop. Split-K cuts the K
reduction across several blocks per output tile; each computes a partial sum, and they combine at the end. It adds a
K_s BLOCK tier above the output tiles, shortens each block's SERIAL_OUTER loop to 1/SPLITK of K, and turns the
Write into a guarded atomic accumulate:
for k_s in 0..SPLITK BLOCK: # NEW: K split across CTAs
for m_b in 0..M/(BM·FM) BLOCK:
for n_b in 0..N/(BN·FN) BLOCK:
for m_t in 0..BM THREAD:
for n_t in 0..BN THREAD:
Init(acc)
# each CTA: 1/SPLITK of K
for k_o in 0..(K/SPLITK)/BK SERIAL_OUTER:
for k_i in 0..BK STAGE_INNER reduce:
a = load A[m_b·BM + m_t, k_s·(K/SPLITK) + k_o·BK + k_i]
b = load B[k_s·(K/SPLITK) + k_o·BK + k_i, n_b·BN + n_t]
Accum(acc, a*b)
if k_s == 0: Write(C[...], acc) # first contributor writes
else: AtomicAccum(C[...], acc) # the rest add
The compiler emits just that. The diff logger shows the new outer grid tier and the guarded epilogue:
DEPLODOCK_KNOBS="SPLITK=2" \
deplodock compile \
-c "torch.matmul(torch.randn(16,64),torch.randn(64,16))" \
--ir tile -vv | awk '/^>>> t:010/,/^<<< t:010/'
-matmul = LoopOp(x1, x0)
- for a0 in 0..16; for a1 in 0..16
- for a2 in 0..64 (reduce over all of K):
+matmul = TileOp(x1, x0)
+ for a0 in 0..2 ← NEW: the K-split grid dimension
+ for a1 in 0..1; for a2 in 0..1 └ grid
+ for a3, a4 (thread):
+ for a5, a6 (reduce over half of K):
+ acc0 <- add(acc0, multiply(in0, in1))
+ matmul[...] = acc0
In CUDA the combine is an atomicAdd into the output:
if (a0 == 0) matmul[...] = acc0; // first K-split writes
else atomicAdd(&matmul[...], acc0); // the rest accumulate
The
atomicAddis only one of two combine strategies, and the autotuner forks between them (ATOMIC_FREE_SPLITK), picking per shape. Atomics are cheap when there are few of them, but the contention grows withSPLITK · M · N: every split CTA races the other splits on the same output cell. Past some count it is faster to drop the atomics entirely. Each CTA writes its partial into a scratchpartial[SPLITK, M, N]buffer with a plain store (the split index now sits in the write address, so there is no conflict), and a second, bandwidth-bound kernel reduces along the split axis into the output. That two-kernel path trades one extra launch and a round-trip through the partials for zero atomic contention, so it wins when the atomic version would serialize on too many conflicting adds: largeM·Nor a highSPLITK.
Split-K only does anything on a skinny matrix, so we use 128×128×16384 (tiny M·N and enormousK),
where a 32×32 block tile gives only 16 output blocks and leaves 90% of the GPU idle:
DEPLODOCK_KNOBS="BM=16,BN=16,FM=2,FN=2,BK=32,STAGE=11,SPLITK=1" \
deplodock run -c "torch.matmul(torch.randn(128,16384),torch.randn(16384,128))" --bench
A 7.1× win: the 8-way split turns 16 idle-heavy blocks into 128 busy CTAs, and the per-block K loop shrinks to an
eighth. It keeps paying past that too — SPLITK=16 lands at 27 µs and SPLITK=32 at 25 µs, an 11× swing, until the
atomic-combine traffic finally catches up with the occupancy it buys.
Final Kernel
Composed, here is where the compiled kernels land against the cuBLAS kernels they compete with — the fp32 CUTLASS SIMT SGEMM and the fp16 tensor-core HGEMM:
To print the final kernel, you can use the following command:
DEPLODOCK_KNOBS="BM=8,BN=32,FM=26,FN=4,BK=32,SPLITK=1,TMA=1,STAGE=11" \
deplodock compile \
-c "torch.matmul(torch.randn(2048,2048),torch.randn(2048,2048))" \
--ir cuda
Abbreviated and reflowed below — the 104-cell FMA cluster and the 26 epilogue stores repeat, and the PTX helper
wrappers (mbarrier_*, cp_async_bulk_tensor_2d) are elided:
extern "C" __global__ __launch_bounds__(256)
void k_matmul(const float* x1, const float* x0, float* matmul,
const CUtensorMap* __restrict__ x1_smem_desc,
const CUtensorMap* __restrict__ x0_smem_desc) {
// 86 KB smem: two double-buffered slabs + the mbarriers
extern __shared__ __align__(16) unsigned char _smem_pool[];
// CTA swizzle (GROUP_M=8): group M tiles for L2 A-row reuse
int bid = blockIdx.x, gsz = 8 * 16, gid = bid / gsz;
int fm = gid * 8, gm = min(8, 10 - fm);
int a0 = fm + (bid % gsz) % gm; // block row
int a1 = (bid % gsz) / gm; // block col
int a2 = threadIdx.x / 32;
int a3 = threadIdx.x % 32;
float* x1_smem = (float*)(_smem_pool + 0);
float* x0_smem = (float*)(_smem_pool + 32768);
unsigned long long* tma_mbar =
(unsigned long long*)(_smem_pool + 86016);
if (threadIdx.x == 0) {
mbarrier_init(&tma_mbar[0], 2);
mbarrier_init(&tma_mbar[1], 2);
}
__syncthreads();
// register tile: 104 cells = FM·FN = 26×4
float acc0 = 0.0f;
float acc1 = 0.0f;
// ... acc2 ... acc102 ...
float acc103 = 0.0f;
// pipeline prologue: issue the chunk-0 TMA per operand
if (threadIdx.x == 1) {
mbarrier_arrive_expect_tx(&tma_mbar[0], 16384);
cp_async_bulk_tensor_2d(&x1_smem[0], x1_smem_desc,
a1*128, 0, &tma_mbar[0]);
}
if (threadIdx.x == 0) {
mbarrier_arrive_expect_tx(&tma_mbar[0], 26624);
cp_async_bulk_tensor_2d(&x0_smem[0], x0_smem_desc,
0, a0*208, &tma_mbar[0]);
}
for (int a7 = 0; a7 < 63; a7++) { // 63 K-chunks, BK=32
// wait for this chunk's TMA to land, then consume it
mbarrier_wait_parity(&tma_mbar[a7%2], a7/2%2);
__syncthreads();
#pragma unroll
for (int a4 = 0; a4 < 32; a4++) { // BK reduction
// B strip (FN=4 cols) + A strip (FM=26 rows): 30 loads
float in0 = x1_smem[a7%2*4096 + a4*128 + a3*4];
float in1 = x0_smem[a7%2*6656 + a2*832 + a4];
float in2 = x0_smem[a7%2*6656 + a2*832 + 32 + a4];
// ... in3 ... in26 (A rows 2..25) ...
float in27 = x1_smem[a7%2*4096 + a4*128 + a3*4 + 1];
float in28 = x1_smem[a7%2*4096 + a4*128 + a3*4 + 2];
float in29 = x1_smem[a7%2*4096 + a4*128 + a3*4 + 3];
// the 26×4 outer product: 104 products
float v0 = in0 * in1;
float v1 = in0 * in2;
// ... v2 ... v102 ...
float v103 = in26 * in29;
// accumulate into the register tile
acc0 += v0;
acc1 += v1;
// ... acc2 ... acc102 ...
acc103 += v103;
}
// prefetch chunk a7+1 into the other buffer
if (threadIdx.x == 1) {
mbarrier_arrive_expect_tx(&tma_mbar[(a7+1)%2], 16384);
cp_async_bulk_tensor_2d(&x1_smem[(a7+1)%2*4096],
x1_smem_desc, a1*128, (a7+1)*32,
&tma_mbar[(a7+1)%2]);
}
if (threadIdx.x == 0) {
mbarrier_arrive_expect_tx(&tma_mbar[(a7+1)%2], 26624);
cp_async_bulk_tensor_2d(&x0_smem[(a7+1)%2*6656],
x0_smem_desc, (a7+1)*32, a0*208,
&tma_mbar[(a7+1)%2]);
}
}
// pipeline epilogue: drain + consume the last chunk
mbarrier_wait_parity(&tma_mbar[1], 1);
// ... the same 30 loads -> 104 FMAs, once more ...
// vectorized epilogue: 26 guarded float4 stores
if (a0*208 + a2*26 + 0 < 2048)
*(float4*)&matmul[(a0*208+a2*26+0)*2048 + a1*128+a3*4]
= make_float4(acc0, acc26, acc52, acc78);
if (a0*208 + a2*26 + 1 < 2048)
*(float4*)&matmul[(a0*208+a2*26+1)*2048 + a1*128+a3*4]
= make_float4(acc1, acc27, acc53, acc79);
// ... rows 2 ... 24 ...
if (a0*208 + a2*26 + 25 < 2048)
*(float4*)&matmul[(a0*208+a2*26+25)*2048 + a1*128+a3*4]
= make_float4(acc25, acc51, acc77, acc103);
}
The fp16 path is a different shape of kernel — warp-specialized tensor cores rather than scalar FMAs. Same command, with the golden fp16 knob set:
M="torch.randn(2048,2048,dtype=torch.float16,device='cuda')"
DEPLODOCK_KNOBS="TMA=1,ATOM_KIND=mma_m16n8k16_f16,WM=1,WN=4,FM=4,FN=2,BK=2,BUFFER_COUNT=2,WARP_SPECIALIZE=1,SPLITK=1" \
deplodock compile \
--code "a=$M;b=$M;torch.matmul(a,b)" \
--ir cuda
160 threads = one producer warp + four consumer warps; the operands are __half, the accumulators stay fp32, and the
inner loop is an mma.sync chain. Abbreviated below — the ldmatrix XOR-swizzle address math, the eight-way mma
fan-out, and the sixteen __half2 epilogue stores repeat, and the PTX helper wrappers (dpl_ldmatrix_*, dpl_mma_*,
mbarrier_*, cp_async_bulk_tensor_2d) are elided:
extern "C" __global__ __launch_bounds__(160)
void k_matmul(const __half* b, const __half* a, __half* matmul,
const CUtensorMap* __restrict__ b_smem_desc,
const CUtensorMap* __restrict__ a_smem_desc) {
// CTA swizzle (GROUP_M=8), same as the fp32 kernel
int bid = blockIdx.x, gsz = 8 * 32, gid = bid / gsz;
int fm = gid * 8, gm = min(8, 32 - fm);
int a0 = fm + (bid % gsz) % gm; // block row
int a1 = (bid % gsz) / gm; // block col
int warp = threadIdx.x / 32, lane = threadIdx.x & 31;
// two double-buffered fp16 slabs + a full/empty mbarrier ring
__shared__ __align__(128) __half b_smem[4096]; // 2 x 32x64
__shared__ __align__(128) __half a_smem[4096];
__shared__ unsigned long long full[2], empty[2]; // producer<->consumer handshake
if (threadIdx.x == 0) {
mbarrier_init(&full[0], 2); mbarrier_init(&full[1], 2);
mbarrier_init(&empty[0], 1); mbarrier_init(&empty[1], 1);
}
__syncthreads();
if (warp == 0) { // ---- producer warp ----
asm volatile("setmaxnreg.dec.sync.aligned.u32 24;\n"); // yield registers
// prologue: issue the chunk-0 TMA per operand
if (threadIdx.x == 1) { mbarrier_arrive_expect_tx(&full[0], 4096);
cp_async_bulk_tensor_2d(&b_smem[0], b_smem_desc, a1*64, 0, &full[0]); }
if (threadIdx.x == 0) { mbarrier_arrive_expect_tx(&full[0], 4096);
cp_async_bulk_tensor_2d(&a_smem[0], a_smem_desc, 0, a0*64, &full[0]); }
for (int k = 0; k < 63; k++) { // issue chunk k+1 once its slot drains
if (k >= 1) mbarrier_wait_parity(&empty[(k+1)%2], ((k+1)/2 - 1)%2);
if (threadIdx.x == 1) { mbarrier_arrive_expect_tx(&full[(k+1)%2], 4096);
cp_async_bulk_tensor_2d(&b_smem[(k+1)%2*2048], b_smem_desc,
a1*64, (k+1)*32, &full[(k+1)%2]); }
if (threadIdx.x == 0) { /* same for a_smem */ }
}
} else { // ---- consumer warps (x4) ----
asm volatile("setmaxnreg.inc.sync.aligned.u32 240;\n"); // claim registers
int wn = (warp - 1) % 4; // WM=1, so WN=4 warps tile N
float acc[8][4] = {}; // FM*FN = 4x2 = 8 atoms, fp32
unsigned a_frag[4][4], b_frag[2][2];
for (int k = 0; k < 63; k++) {
mbarrier_wait_parity(&full[k%2], k/2%2); // wait for this chunk's TMA
asm volatile("bar.sync 1, 128;\n"); // consumer-only barrier (128 thr)
for (int a3 = 0; a3 < 2; a3++) { // 2 k-atoms per BK chunk
// ldmatrix with the XOR swizzle that matches the TMA smem layout
ldmatrix_x4(a_frag[0], &a_smem[swizzle(k%2, a3, lane)]);
// ... a_frag[1..3] ...
ldmatrix_x2_trans(b_frag[0], &b_smem[swizzle(k%2, wn, a3, lane)]);
// ... b_frag[1] ...
// 4x2 outer product of atoms = 8 mma.sync, fp16 in -> fp32 out
mma_m16n8k16(acc[0], a_frag[0], b_frag[0], acc[0]);
// ... acc[1] ... acc[6] ...
mma_m16n8k16(acc[7], a_frag[3], b_frag[1], acc[7]);
}
asm volatile("bar.sync 1, 128;\n");
if (threadIdx.x == 32) mbarrier_arrive(&empty[k%2]); // signal slot free
}
// ... epilogue: drain + consume the last chunk, once more ...
// store the fp32 accumulators as __half2 (16 guarded stores)
int g = lane >> 2, t = lane & 3;
*(__half2*)&matmul[(a0*64)*2048 + a1*64 + wn*16 + g*2048 + t*2]
= __floats2half2_rn(acc[0][0], acc[0][1]);
// ... 15 more ...
}
}
References
Hand-Written Matmul Worklogs
- Simon Boehm. How to Optimize a CUDA Matmul Kernel for cuBLAS-like Performance: a Worklog. 2022.
- Outperforming cuBLAS on H100: a Worklog. 2024.
- Lei Mao. CUDA Matrix Multiplication Optimization.
Tensor Cores, TMA, and Pipelining
- NVIDIA. Programming Tensor Cores in CUDA 9.
- Lei Mao. NVIDIA Tensor Core Programming.
- Aman. A gentle introduction to GEMM using MMA tensor cores.
- Colfax Research. CUTLASS Tutorial: Fast Matrix-Multiplication with WGMMA on Hopper.
- SIGARCH. Efficient GEMM Kernel Designs with Pipelining.
- NVIDIA. CUTLASS: Efficient GEMM.
Why Vectorize / Interleave Wash Out (ptxas Internals)
- JuliaGPU/CUDA.jl. ptxas vectorizes scalar
ld.sharedruns once alignment is known (issue #68). - NVIDIA. CUDA Pro Tip: Increase Performance with Vectorized Memory Access (the
float4cast is purely an alignment promise). - NVIDIA Developer Forum. PTX instructions are reordered (ptxas hoists loads early and schedules by its own heuristics).
- NVIDIA Developer Forum. Why vectorized loads are more efficient (wide loads cut instruction count, not bandwidth).
Companion Reading
- Matrix Multiplication — Triton tutorial.
- Surfacing a 60% performance bug in cuBLAS on the RTX 5090.
- Building a GPU Compiler from Scratch, the pipeline behind the microscope.