Surfacing a 60% performance bug in cuBLAS
Every GPU programmer will tell you that you can't beat cuBLAS at matrix multiplication. Matmul is the most popular operation by a large margin, and NVIDIA engineers have squeezed their GPUs dry. Of course, that doesn't stop thousands of engineers, including myself, from playing this unfair sport.
I started this project as a learning exercise: write an FP32 SGEMM kernel for the RTX 5090 (Blackwell, sm_120) using the new TMA hardware introduced in Hopper and reach 80-90% of cuBLAS performance. That was the plan.
While benchmarking, the batched-mode numbers on the 5090 came out 50–60% above cuBLAS — at every size from 1024 to 8192. That seemed suspiciously good for a learning exercise. So I profiled with ncu to see what was happening, and found that cuBLAS was dispatching a tiny simt_sgemm_128x32_8x5 kernel for the entire range of batched workloads, running at only 41% FMA pipe utilization (essentially using only 41% of available compute throughput).
I double-checked it on other GPUs and found out that the same libcublas.so binary uses a larger simt_sgemm_256x128_8x4 kernel at 73% FMA pipe utilization on the RTX PRO 6000, and an even better xmma_gemm family at 82% on the H200. RTX GPUs clearly receive less love from NVIDIA.
The reference kernel that I wrote using the new Blackwell feature — TMA (Tensor Memory Accelerator) — is still interesting. It hits ~68% FMA pipe utilization with ~300 lines of generated C, where CUTLASS's hand-tuned kernels need thousands of lines of templates to hit 73%. I will break down the TMA implementation to show how you can hit ~80-120% of cuBLAS performance with 10x less code than traditional templated approaches
Data and implementation are available in the DeploDock repository — GPU and LLM deployment, benchmarking, and optimization framework.
The Headlines
Single matmul on RTX 5090 — my kernel matches cuBLAS within 5 percentage points of FMA pipe utilization on every size (256 and 512 omitted; the per-call duration is too short and measurement variance is too high):
| Size | TM | BK | KS | Kernel ms | cuBLAS ms | Eff |
|---|---|---|---|---|---|---|
| 1024 | 8 | 32 | 1 | 0.046 | 0.044 | 96% |
| 2048 | 26 | 32 | 1 | 0.234 | 0.248 | 106% |
| 4096 | 20 | 32 | 1 | 2.213 | 2.214 | 100% |
| 8192 | 28 | 32 | 1 | 17.558 | 16.581 | 94% |
| 16384 | 28 | 32 | 1 | 147.607 | 131.991 | 89% |
Batched matmul on RTX 5090 — 1.4–1.7× cuBLAS across the board:
| Size | B=4 | B=8 | B=16 |
|---|---|---|---|
| 256 | 91% | 80% | 90% |
| 512 | 120% | 153% | 135% |
| 1024 | 137% | 142% | 142% |
| 2048 | 158% | 155% | 157% |
| 4096 | 157% | 162% | 170% |
| 8192 | 158% | 152% | 148% |
The batched table is where it gets weird. Here's the same cublasSgemmStridedBatched call on three different sm_90/sm_120 GPUs at batch=8, captured by ncu, showing the dispatched kernel and its FMA pipe utilization:
| B=8 | 5090 kernel | FMA% | Pro 6000 kernel | FMA% | H200 kernel | FMA% |
|---|---|---|---|---|---|---|
| 256 | simt_128x32_8x5 | 33% | magma_Ex | 32% | xmma_32x32x8 | 33% |
| 512 | simt_128x32_8x5 | 39% | magma_Ex | 32% | xmma_64x128x8 | 69% |
| 1024 | simt_128x32_8x5 | 41% | simt_128x64_8x5 | 64% | simt_256x128_8x4 | 78% |
| 2048 | simt_128x32_8x5 | 41% | simt_128x128_8x4 | 69% | simt_256x128_8x4 | 79% |
| 4096 | simt_128x32_8x5 | 42% | simt_256x128_8x4 | 73% | xmma_128x128x8 | 82% |
| 8192 | simt_128x32_8x5 | 42% | simt_256x128_8x4 | 73% | xmma_128x128x8 | 82% |
It is no surprise that cuBLAS schedules a different kernel for different matrix sizes. Kernels might perform differently on different matrix sizes, so cuBLAS tries to choose the best one. However, the behavior on different GPUs is quite different.
-
H200 (Hopper, sm_90) mixes the open-source CUTLASS template family at 1024–2048 with NVIDIA's closed-source
xmma_gemmfamily at 4096+. Withinxmma_gemmit picks three different tile sizes (32×32 → 64×128 → 128×128) escalating with workload. Peak hits 82% FMA pipe utilization. -
RTX PRO 6000 Blackwell Max-Q (sm_120) escalates within the CUTLASS family through three different tile sizes (128×64 → 128×128 → 256×128) climbing from 64% to 73% FMA pipe utilization. Less sophisticated than H200, but still good. The one bug: at 256 / 512 it falls into a legacy
magma_sgemmEx_kernelcode path at 32% FMA pipe util. (MAGMA was NVIDIA's pre-CUTLASS linear algebra library from the early 2010s, largely absorbed into cuBLAS — the fact that its kernels still appear in the dispatch path on a 2026 GPU is a window into how deep the legacy debt goes in NVIDIA's stack.) -
RTX 5090 (sm_120) picks the same
simt_sgemm_128x32_8x5kernel for every workload from 256×256 (≈microsecond per call) all the way to 8192×8192×8 batches (≈0.5 seconds per call). FMA pipe utilization stuck in the 33–42% band across the entire 32× range of linear dimensions.
This isn't a wrong threshold somewhere in the dispatcher. There's no escalation at any threshold. The escalation logic for the 5090 sm_120 batched FP32 path is missing entirely.
I haven't tested kernels on other RTX GPUs like 5070 or 4090, but it is likely that the bug is present on all consumer GPUs.
What About cuBLASLt and Tensor Cores?
cuBLASLt is NVIDIA's "lightweight" BLAS API that exposes more control than plain cuBLAS — you can query available algorithms, set workspace sizes, and force specific compute modes. A natural question: can cuBLASLt's algorithm heuristics route around the 5090 batched-dispatch bug? And what about hybrid approaches using tensor cores with FP32 accumulators?
I tested all cuBLASLt compute modes at 4096×4096:
| Mode | Kernel | TFLOPS | Precision |
|---|---|---|---|
| COMPUTE_32F | simt_sgemm_128x128 | 70.1 | Exact FP32 |
| COMPUTE_32F_FAST_TF32 | tensorop_s1688gemm | 95.4 | TF32 inputs (10-bit mantissa) |
| COMPUTE_32F_FAST_16BF | tensorop_s1688gemm | 103.6 | BF16 inputs (7-bit mantissa) |
The FP32 path is locked to SIMT regardless of heuristic settings — cuBLASLt picks a simt_sgemm with a different tile (128×128 vs 256×128) but still cooperative cp.async loading, no TMA, and still no path to the dispatcher's broken heuristic. The FAST_TF32/BF16 modes switch to tensor cores (tensorop_s1688gemm) and are 36–48% faster — but with reduced input precision. Note all three are cutlass_80-prefixed Ampere-era kernels.
For strict FP32 accuracy, tensor cores aren't an option. TF32 truncates to 10-bit mantissa; BF16 to 7-bit. If your workload tolerates ~0.1% relative error, FAST_TF32 is the pragmatic choice. For exact FP32, the cuBLAS dispatcher bug applies and there's no public API to work around it without writing your own kernel.
Where my Kernel Fits In
My TMA template hits ~68% FMA pipe utilization on every Blackwell SKU we tested and ~71% on Hopper, which means it is about 10% behind cuBLAS where scheduler chooses an efficient kernel and 40-60% ahead of underperforming kernels on RTX 5090.
| Workload | cuBLAS FMA% | Mine | Ratio | Observed eff |
|---|---|---|---|---|
| 5090 batched 4K b=8 | 42% | 67% | 1.60× | 158% ✓ |
| 5090 batched 8K b=8 | 42% | 68% | 1.62× | 159% ✓ |
| Pro 6000 4K b=8 | 73% | 68% | 0.93× | 93% ✓ |
| Pro 6000 8K b=8 | 73% | 68% | 0.93× | 95% ✓ |
| H200 batched 4K b=8 | 82% | 71% | 0.86× | 91% ✓ |
| H200 batched 8K b=8 | 82% | 71% | 0.87× | 87% ✓ |
| 5090 single 8K | 73% | 68% | 0.93× | 95% ✓ |
| H200 single 8K | 79% | 71% | 0.90× | 92% ✓ |
I will introduce my kernel now and the technologies used to make it work. To enjoy the following section of this article, it is good to familiarize yourself with general techniques for optimizing Matmul kernel on GPU. The How to Optimize a CUDA Matmul Kernel for cuBLAS-like Performance by Simon Boehm is a good starting point.
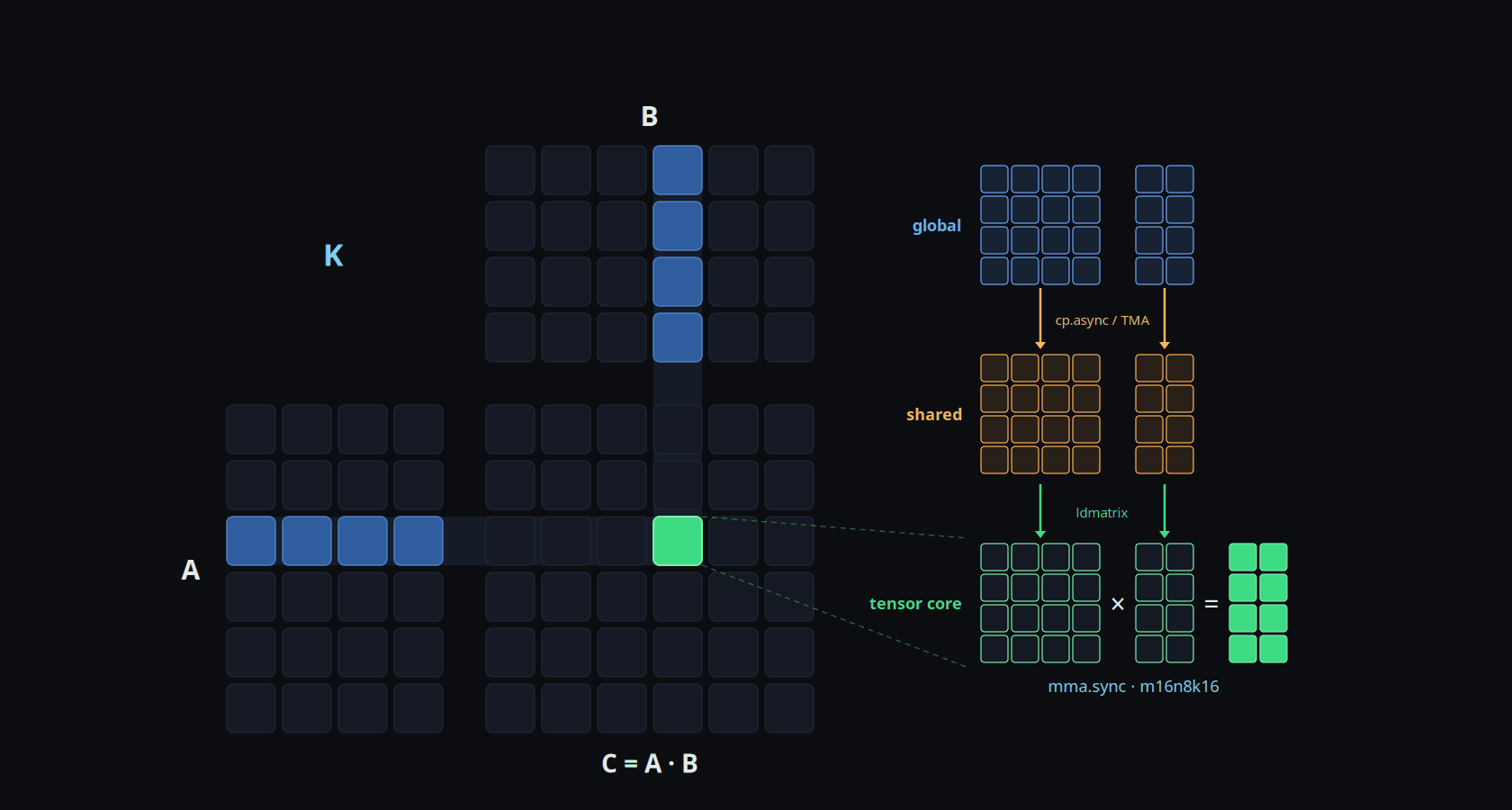
TMA vs LDGSTS: A Quick Primer
If you're not deep in GPU programming, here's the key distinction.
High-performance matmul kernels tile the computation: load a block of A and B from global memory (slow, ~1 TB/s) into shared memory (fast, ~20 TB/s), compute the partial products from shared memory, repeat. The bottleneck is getting data from global to shared memory efficiently. NVIDIA provides two hardware mechanisms for this — both asynchronous memory copies that bypass registers and transfer data directly.
LDGSTS (cp.async) is the traditional way to load data from global memory into shared memory. Every thread in the block participates: thread 0 loads element 0, thread 1 loads element 1, and so on. It's cooperative — 256 threads each issue their own load instruction, generating 256 individual memory transactions. The hardware coalesces these into efficient cache-line transfers, but each thread still spends instruction slots on address computation, load issuance, and shared memory stores. CUTLASS and cuBLAS have used this approach since Ampere.
TMA (Tensor Memory Accelerator) is new hardware introduced in Hopper (sm_90) and refined in Blackwell (sm_120). Instead of 256 threads each loading one element, a single thread issues one cp.async.bulk.tensor.2d command that describes the entire 2D tile — "load a 32×224 block of floats starting at row R, column C." The TMA hardware unit, separate from the CUDA cores, handles the entire transfer via DMA. The other 255 threads contribute zero instructions — they can compute while the load happens in the background. Blackwell's TMA unit shares the same PTX interface as Hopper's; the practical difference I observed is that Blackwell favors larger per-thread tiles (TM=28 is optimal on the 5090 vs TM=8 on the H200), suggesting the sm_120 TMA unit has lower per-issue overhead or better pipelining of concurrent descriptors.
In principle, TMA should be faster than LDGSTS because it removes per-thread loading overhead. In practice, on the workloads I measured, TMA and well-tuned LDGSTS land within 5% of each other at the FMA pipe utilization level. What TMA actually buys you is kernel implementation simplicity — you can write a fully-pipelined SGEMM kernel in ~300 lines of generated C, vs the thousands of lines of templated C++ that CUTLASS needs.
The TMA Double-Buffer Architecture
On Blackwell, the TMA hardware unit can load a 2D tile from global memory to shared memory with a single PTX instruction. One thread issues cp.async.bulk.tensor.2d, the hardware does the rest.
The kernel uses this in a double-buffer pipeline:
Tile 0: [TMA loads buf0] [wait] [compute buf0 + TMA loads buf1]
Tile 1: [wait buf1] [compute buf1 + TMA loads buf0]
Tile 2: [wait buf0] [compute buf0 + TMA loads buf1]
...
While all 256 threads compute FMAs from the current buffer, thread 0 issues a TMA command to fill the other buffer. The TMA hardware runs on a separate path from the CUDA cores — true parallel execution.
Here's the simplified kernel structure (TM=8 variant, 32 accumulators):
__global__ __launch_bounds__(256)
void fused_matmul(
const __grid_constant__ CUtensorMap A_tma,
const __grid_constant__ CUtensorMap B_tma,
float* C)
{
extern __shared__ __align__(128) char dsmem[];
float* smem = (float*)dsmem;
// Two mbarriers for double-buffer synchronization
uint64_t* mbar = (uint64_t*)(dsmem + 2 * STAGE * 4);
// Shared memory addresses for TMA targets
const int as0 = __cvta_generic_to_shared(&smem[0]);
const int bs0 = __cvta_generic_to_shared(&smem[A_SIZE]);
const int as1 = __cvta_generic_to_shared(&smem[STAGE]);
const int bs1 = __cvta_generic_to_shared(&smem[STAGE + A_SIZE]);
// Thread identity
int tid = threadIdx.y * 32 + threadIdx.x;
int tr = threadIdx.y * TM, tc = threadIdx.x * 4;
int bm = blockIdx.y * BM, bn = blockIdx.x * BN;
// Initialize mbarriers (thread 0 only)
if (tid == 0) {
mbarrier_init(mbar[0]); mbarrier_init(mbar[1]);
}
__syncthreads();
float c[TM][4] = {}; // Accumulators
// Pre-load first tile
if (tid == 0) {
mbarrier_expect_tx(mbar[0], BYTES);
tma_load_2d(as0, &A_tma, /*k=*/0, bm, mbar[0]);
tma_load_2d(bs0, &B_tma, bn, /*k=*/0, mbar[0]);
}
for (int t = 0; t < K/BK; t++) {
int s = t % 2; // Current buffer
// Wait for current tile's TMA to complete
mbarrier_wait(mbar[s], phase[s]);
// Start loading NEXT tile (overlaps with compute)
if (tid == 0 && t + 1 < nt) {
tma_load_2d(next_buf_a, &A_tma, next_k, bm, next_mbar);
tma_load_2d(next_buf_b, &B_tma, bn, next_k, next_mbar);
}
// Compute: all 256 threads do FMA from shared memory
float* As = &smem[s * STAGE];
float* Bs = &smem[s * STAGE + A_SIZE];
#pragma unroll
for (int kk = 0; kk < BK; kk++) {
float b0 = Bs[kk*BN+tc], b1 = Bs[kk*BN+tc+1], ...;
for (int i = 0; i < TM; i++) {
float a = As[(tr+i)*BK+kk];
c[i][0] += a * b0;
c[i][1] += a * b1;
// ... 4 FMAs per row
}
}
__syncthreads();
}
// Write results to global memory
for (int i = 0; i < TM; i++)
store_row(C, bm+tr+i, bn+tc, c[i]);
}
The actual generated kernel is denser (inline PTX for mbarrier and TMA operations), but this captures the architecture. You can find the kernel generator in deplodock/compiler/cuda/lower.py (see _lower_matmul_tma_db).
Compile-Time Specialization
A useful optimization is to make M, N, K #define constants, and not kernel parameters. The runner generates a fresh .cu file for each benchmark invocation with the actual dimensions baked in:
#define M 8192
#define N 8192
#define K 8192
__global__ void fused_matmul(...) {
// nt = K/32 becomes nt = 256 — a literal constant
// Bounds checks become dead code for aligned sizes
}
This lets nvcc optimize the tile loop bound, eliminate unreachable branches, and make better register allocation decisions. Moving M/N/K from runtime parameters to compile-time constants improved 1024 from 98% to 101% and 4096 from 100% to 101%.
Similarly, the write-back bounds checks (if (gr < M), if (gc < N)) are eliminated via #if when the matrix dimensions are multiples of the tile size:
#if (M % 224 == 0 && N % 128 == 0)
#define W(r, v0, v1, v2, v3) { /* no bounds checks */ }
#else
#define W(r, v0, v1, v2, v3) { /* with bounds checks */ }
#endif
In practice, this compile-time specialization makes sense for a set of common sizes (powers of 2, standard model dimensions) rather than generating a kernel for every possible M/N/K.
Size-Adaptive Tile Selection
Different matrix sizes have different optimal tile shapes. An adaptive strategy map selects the best configuration per size. These were found empirically by benchmarking various configurations on each GPU. For RTX 5090:
| Size | TM | BM×BN | Why |
|---|---|---|---|
| 256-512 | 8 | 64×128 | K-splitting (blockIdx.z) for grid parallelism |
| 1024 | 8 | 64×128 | Small tile, high block count for 170 SMs |
| 2048 | 26 | 208×128 | Large tile hides TMA latency |
| 4096 | 20 | 160×128 | Sweet spot between tile size and grid coverage |
| 8192+ | 28 | 224×128 | Maximum compute density per thread |
At TM=28, each thread computes 28×4 = 112 output elements, requiring 112 accumulator registers. The inner loop is fully unrolled (BK=32 iterations), and the compiler uses 241 registers total — close to the sm_120 limit of 255.
CTA Swizzle for L2 Cache Reuse
At 16384×16384, the working set is 3 GB — far beyond the 72 MB L2 cache. Without careful block scheduling, different blocks evict each other's L2 lines. I linearize the grid and rasterize in groups of 8 row-tiles:
const int SWIZ = 8;
int pid = blockIdx.x;
int grp = pid / (gridDim.x * SWIZ);
int rem = pid % (gridDim.x * SWIZ);
int by = grp * SWIZ + rem % SWIZ; // Row block
int bx = rem / SWIZ; // Column block
This ensures 8 adjacent row-blocks run together, maximizing reuse of A-tiles in L2. ncu profiling confirmed this reduced DRAM throughput from 32% to 8.5% — matching cuBLAS's 8.2%.
Batched mode
Batched mode is a one-line change: blockIdx.z selects the batch element, each batch gets its own TMA descriptor:
int batch = blockIdx.z;
const CUtensorMap& A_tma = A_tma_array[batch];
// ... same kernel, different data
float* C_batch = C + batch * M * N;
NCU Comparison with cuBLAS
All measurements: CUDA 13.2.51, cuBLAS 13.3.0, driver 595.58.03, captured by scripts/diagnostics/ncu_compare.sh.
A quick glossary for the metrics: IPC (instructions per cycle) measures how many instructions the SM issues per clock — higher is better, max ~4.0 on sm_120. FMA pipe is the percentage of cycles the fused multiply-add units are active — this is the actual compute throughput. Issue active is the percentage of cycles where at least one warp scheduler successfully issues an instruction — gaps here mean all warps are stalled.
For single matmul at 8192:
| Metric | RTX 5090 — TMA | RTX 5090 — cuBLAS | H200 — TMA | H200 — cuBLAS |
|---|---|---|---|---|
| Kernel name | fused_matmul | simt_sgemm_... | fused_matmul | xmma_gemm_... |
| Cycles active (M) | 37.6 | 34.8 | 45.7 | 41.1 |
| IPC | 2.95 | 3.23 | 3.26 | 3.57 |
| FMA pipe utilization | 68.0% | 72.9% | 71.3% | 79.2% |
| Issue active | 100% | 100% | 100% | 100% |
| Warps active | 16.7% | 16.7% | 37.1% | 12.5% |
| DRAM throughput | ~8% | ~8% | 5.3% | 4.7% |
| Registers / thread | 241 | 210 | 80 | 254 |
| Smem / block | 89 KB | 49 KB | 49 KB | 67 KB |
| Effective TM | 28 | (256x128 tile) | 8 | (256x128 tile) |
| Blocks per SM | 1 | 1 | 3 | 1 |
The performance gap maps directly to the FMA pipe gap. On the 5090 single mode, cuBLAS hits 72.9% FMA pipe utilization vs my 68.0% — a ~5% gap, which matches the ~5% efficiency gap in the headline tables (cycles_active: 34.8 M vs 37.6 M = 92.6% ratio). On the H200 single mode, cuBLAS hits 79.2% vs my 71.3% — a ~8% gap, matching the ~10% efficiency gap (cycles_active: 41.1 M vs 45.7 M = 89.9% ratio). It's not bandwidth (DRAM throughput is 5–8%, nowhere near the limit). It's not issue-active (both kernels are at 100%). It's purely how many of the issued instructions actually land in the FMA pipe.
Cross-checking Against the Headline Efficiencies
The batched mode comparison is already covered in the headline section. The findings are the same: the performance gap maps directly to the FMA pipe gap. Putting the per-arch FMA pipe numbers next to the observed efficiencies:
| Workload | cuBLAS FMA% | Mine FMA% | Ratio | Observed eff |
|---|---|---|---|---|
| 5090 batched 4K b=8 | 42% | 67% | 1.60× | 158% ✓ |
| 5090 batched 8K b=8 | 42% | 68% | 1.62× | 159% ✓ |
| Pro 6000 batched 4K b=8 | 73% | 68% | 0.93× | 93% ✓ |
| Pro 6000 batched 8K b=8 | 73% | 68% | 0.93× | 95% ✓ |
| H200 batched 4K b=8 | 82% | 71% | 0.86× | 91% ✓ |
| H200 batched 8K b=8 | 82% | 71% | 0.87× | 87% ✓ |
| 5090 single 8K | 73% | 68% | 0.93× | 95% ✓ |
| H200 single 8K | 79% | 71% | 0.90× | 92% ✓ |
| Pro 6000 single 4K | 73% | 69% | 0.94× | 93% ✓ |
The full ncu sweep with raw per-row data is committed in the recipe directory at recipes/sgemm_cublas_vs_tma/ncu/batched_dispatch_finding.md, reproducible with scripts/diagnostics/ncu_compare.sh.
We Need to Go Deeper: Beyond PTX
The article so far has the headline numbers and the dispatcher-bug evidence. Both are about which kernel runs and how the GPU dispatches it. Neither answers the more refined question: when cuBLAS does dispatch the right kernel — cutlass_80_simt_sgemm_256x128_8x4_nn_align1 on the 5090 single-mode path — why does it consistently hit ~73% FMA pipe utilization while my generated TMA template gets ~68%? This section is the SASS-level investigation that produced a measured answer, and walks through the reproducible scripts that surface it.
All numbers below come from running on RTX 5090, CUDA 13.2.51, cuBLAS 13.3.0, single mode 8192×8192. The full per-instruction ncu source view, the per-kernel stall histograms, and the inner-loop SASS excerpts are committed in recipes/sgemm_cublas_vs_tma/ncu/scheduling/ so you can re-derive them yourself.
Static Instruction Histograms
scripts/diagnostics/sass_analysis.py compiles a fresh tma_db bench binary, runs cuobjdump --dump-sass, and counts opcodes by family. For my fused_matmul (TM=28, BK=32) at 8192×8192:
3584 FFMA — fused multiply-add (the actual compute)
256 LDS.128 — 128-bit shared memory loads (float4)
112 STG.E — 32-bit predicated global stores (4 per row × 28 rows,
bounds-checked because 8192 % 224 ≠ 0; an aligned size
collapses to 28 STG.E.128 via nvcc auto-vectorization)
48 CS2R / S2R — clock + special-register reads
4 UTMALDG.2D — TMA load commands (the entire loading!)
143 ISETP.* — integer set-predicate (bounds + loop control)
60 BAR/BSYNC/BSSY — block barriers and reconvergence
30 LDC.* — constant loads (kernel params, TMA descriptors)
169 MOV/IMAD/IADD/LEA — address arithmetic and reg copies
cuBLAS's cutlass_80_simt_sgemm_256x128_8x4_nn_align1 ships as a PTX template inside libcublasLt.so and JIT-compiles at runtime. To see its actual SASS, capture the cubin via ncu while the kernel is running (ncu --set full --print-units base -o profile.ncu-rep ./cublas_probe, then ncu --import profile.ncu-rep --page source --print-source sass). The result has 1152 FFMAs and 256 LDS in the kernel body — a third of my FFMA count, because cuBLAS uses a smaller per-thread tile (more CTAs, fewer FMAs per thread). The notable structural fact: 0 shared-memory store instructions in mine, 256 in cuBLAS (cuBLAS pipelines through smem with cp.async + st.shared, my TMA hardware writes smem directly via DMA). That's the one place TMA buys a real instruction-count saving.
LDS-to-consumer Scheduling
The first hypothesis I tested was the obvious one: maybe ptxas places LDS loads too close to their consumer FFMAs, and the warp scheduler stalls waiting for the load to complete. To check, I extended the diagnostic with scripts/diagnostics/scheduling_analysis.py — it parses the disassembly, walks each LDS.* forward through the instruction stream, and finds the first downstream FFMA that uses any of the loaded registers. The distance between the load and its consumer is your latency-hiding budget.
For my fused_matmul at 8192:
| FFMAs between LDS and first consumer | Count |
|---|---|
| [0, 5) | 3 |
| [5, 10) | 1 |
| [10, 20) | 13 |
| [20, 40) | 110 |
| [40, 80) | 117 |
| [80, 160) | 11 |
| [160, ∞) | 1 |
Median 40 FFMAs, mean 44.6, only 4 of 256 LDS have a consumer within 10 FFMAs. Blackwell LDS latency is on the order of 30 cycles, and each FFMA is one cycle on the FMA pipe, so ptxas is hiding LDS latency essentially perfectly. The "ptxas places LDS too close to consumers" hypothesis was wrong. That's not where the gap is.
Running the same analysis on the cuBLAS kernel (extracted from the ncu source view) gives a completely different shape:
| mine | cuBLAS | |
|---|---|---|
| FFMAs in kernel body | 3584 | 1152 |
| LDS instructions | 256 | 256 |
| LDS / FFMA ratio | 1 per 14 | 1 per 4.5 |
| Median LDS → first consumer | 40 FFMAs | 158 FFMAs |
| Median LDS → next LDS spacing | 5 FFMAs | 0 FFMAs |
cuBLAS's median LDS-to-next-LDS spacing is zero — its LDS instructions are clustered into back-to-back groups. My kernel spreads LDS evenly through the FFMA cluster, with median 5 FFMAs between consecutive loads. Both schedules hide LDS latency well (40 vs 158 FFMAs is overkill in both cases for a 30-cycle load), but they produce fundamentally different warp behaviors at runtime.
The difference matters because of how it affects warp staggering across the SM's warp schedulers:
cuBLAS schedule (clustered LDS):
warp 0: [LDS LDS LDS LDS LDS LDS] [FFMA FFMA FFMA FFMA FFMA FFMA FFMA ...]
warp 1: [LDS LDS LDS LDS LDS LDS] [FFMA FFMA FFMA FFMA FFMA ...]
warp 2: [LDS LDS LDS LDS LDS LDS] [FFMA FFMA FFMA FFMA ...]
← warps naturally stagger: while warp 0 does FFMAs, warp 1 is in
its LDS cluster, so the FMA pipe sees steady demand from ONE warp
at a time → low dispatch_stall
My schedule (interleaved LDS):
warp 0: [FFMA FFMA FFMA FFMA LDS FFMA FFMA FFMA FFMA LDS FFMA FFMA ...]
warp 1: [FFMA FFMA FFMA FFMA LDS FFMA FFMA FFMA FFMA LDS FFMA FFMA ...]
warp 2: [FFMA FFMA FFMA FFMA LDS FFMA FFMA FFMA FFMA LDS FFMA FFMA ...]
← all warps are in the SAME phase: they all want the FMA pipe on
the same cycles → high dispatch_stall (44% vs 22%)
You can see the difference in the actual inner-loop SASS excerpts. Here's a 30-line slice from cuBLAS's cutlass_80_simt_sgemm_256x128 (recipes/sgemm_cublas_vs_tma/ncu/scheduling/cublas_inner_loop_excerpt.txt):
**LDS.128 R132, [R130]** ← 6 LDS in a row (clustered)
LDCU.64 UR16, c[0x0][0x3c0]
SHF.R.U32.HI R30, RZ, 0x1, R131
IADD.64 R200, R200, UR4
**LDS.128 R140, [R130+0x40]**
LDCU.64 UR14, c[0x0][0x3e0]
LOP3.LUT R185, R185, 0xffc, R30, 0xc8, !PT
IADD.64 R204, R204, UR10
**LDS.128 R144, [R130+0x80]**
ISETP.NE.AND P0, PT, R189, RZ, PT
MOV R186, RZ
**LDS.128 R148, [R130+0xc0]**
... ← then the FFMA burst
**LDS.128 R156, [R130+0x200]**
FFMA R127, R132, R136, R127 ← consumer arrives 158 FFMAs later in steady state
FFMA R128, R133, R136, R128
FFMA R126, R133, R137, R126
FFMA R125, R132, R137, R125
FFMA R123, R134, R136, R123
... (long FFMA run with occasional single LDS interleaved)
And here's mine (recipes/sgemm_cublas_vs_tma/ncu/scheduling/fused_matmul_inner_loop_excerpt.txt):
FFMA R140, R36, R144, R159 ← FFMAs running
FFMA R158, R37, R144, R158
FFMA R161, R38, R144, R161
FFMA R160, R39, R144, R160
FFMA R144, R36, R148, R163
FFMA R162, R37, R148, R162
FFMA R165, R38, R148, R165
FFMA R164, R39, R148, R164
FFMA R3, R41, R152, R166
**LDS.128 R36, [R15+0x8400]** ← single LDS in the middle of the cluster
FFMA R168, R41, R153, R168
FFMA R167, R41, R154, R167
FFMA R40, R41, R155, R40
FFMA R5, R45, R152, R172
... (continues with one LDS every ~5 FFMAs)
These are two valid SGEMM schedules. Both feed the FMA pipe. They differ in how the warps stagger.
Per-warp stall reasons
I captured the per-warp stall reasons from ncu. The script is scripts/diagnostics/ncu_stall_compare.sh; it builds a small probe binary for both kernels at the same shape and extracts the smsp__average_warps_issue_stalled_*_per_issue_active metrics. Each value is "warps stalled on this reason per issue-active cycle" — sums can exceed 100% when multiple warps stall in parallel.
For 5090 single-mode 8192:
| Stall reason | fused_matmul (mine, TM=28) | cuBLAS 256x128_8x4 | delta |
|---|---|---|---|
| not_selected | 82.23% | 85.14% | +2.9 |
| dispatch_stall | 44.21% | 22.36% | −22 |
| short_scoreboard | 19.95% | 11.84% | −8 |
| mio_throttle | 7.86% | 4.95% | −3 |
| barrier | 7.25% | 6.66% | −0.6 |
| no_instruction | 3.00% | 7.36% | +4 |
| wait | 3.93% | 3.28% | −0.7 |
| long_scoreboard | 1.92% | 1.84% | −0.1 |
| lg_throttle | 0.04% | 2.73% | +2.7 |
| math_pipe_throttle | 0.17% | 1.13% | +1 |
There are two large deltas:
dispatch_stall = 44 % vs 22 %. Dispatch stall happens when the warp scheduler has picked a ready warp but the dispatch unit can't accept another instruction this cycle — typically because some other warp's in-flight FFMA has the FMA pipe back-pressured. My kernel has twice as much dispatch stall as cuBLAS does, and that's the dominant cause of the FMA pipe utilization gap.
short_scoreboard = 20 % vs 12 %. Short scoreboard stalls are dependencies on short-latency operations (LDS reads), where the scheduler is waiting for the scoreboard bit to clear. Even though my static LDS-to-consumer distance is 40 FFMAs (more than enough to hide the latency in isolation), the consumers are tightly interleaved into a long FFMA run, so the scoreboard's temporal hiding is shorter than the static count suggests.
Both deltas point at the same root cause: warp phase alignment. With my spread-LDS pattern, all warps are in roughly the same execution phase at the same time — they all want to execute FFMA instructions on the same cycles. With cuBLAS's clustered-LDS pattern, warps stagger naturally: while warp A is draining a long FFMA run, warp B is in its LDS cluster, warp C is finishing a previous FFMA cluster. The warp scheduler always has a different warp to switch to instead of contending on the FMA pipe.
The performance gap between my kernel and cublas is caused by the temporal distribution of LDS instructions across warps, which determines whether warps stagger or align, which determines how much dispatch-stall pressure piles up on the FMA pipe.
A note on the mbarrier.try_wait spin loop
A common concern with TMA double-buffer schemes: don't threads waste cycles spinning in mbarrier.try_wait? Empirically, no. The TMA transfer for the 45 KB double-buffer slot (bytes=45056 in the kernel source) completes well within the FFMA compute phase, so the try-wait spin loop almost always exits on its first read. The dispatch_stall and short_scoreboard numbers above don't include any meaningful contribution from try-wait spinning — both wait = 3.9% and barrier = 7.3% are small compared to the dispatch-side gap.
Where is the Limit?
The constant 5–11% gap below cuBLAS's best-available kernel (when the dispatcher does its job) shows up on every architecture I tested. I systematically tried to close it. None of these worked:
| Attempt | Result | Why |
|---|---|---|
| Inline PTX FMA instructions | No change | ptxas reschedules regardless of source |
| Partial unroll (#pragma unroll 4/8/16) | Monotonically worse | Fewer registers for ILP = worse scheduling |
| No unroll (let compiler decide) | 57% of cuBLAS | Compiler chooses no unroll — terrible |
__launch_bounds__(256, 2) for 2 blocks/SM | 20× slower | 5.7KB spilling from 128-register limit |
Cooperative cp.async loading | 82.6% | More per-thread overhead than TMA |
Triple-buffer (remove __syncthreads) | Same IPC | Warp lockstep is hardware, not software |
| CTA rasterization for L2 | Fixed DRAM (32%→8.5%) | Verified with ncu, matches cuBLAS |
nvcc flags (-Xptxas variants) | Within noise | ptxas -O3 is already best |
| Binary SASS patching (stall counts) | Broke correctness | Stalls encode real data hazards |
The irreducible gap is in ptxas's instruction scheduling heuristics — specifically, in how it distributes LDS instructions across the FFMA cluster. As measured in the SASS Deep Dive section above, my generated kernel ends up with dispatch_stall = 44 % versus cuBLAS's 22 %, because my LDS pattern is spread evenly through the FFMA cluster (median spacing 5 FFMAs) while cuBLAS's CUTLASS template clusters them into back-to-back groups (median spacing 0).
A Note on FP16 / BF16 - the Mainstream Path
The mainstream compute path on modern GPUs is FP16/BF16, possibly with FP32 accumulators for training. That's where NVIDIA puts the optimization effort. Pure FP32 SGEMM is no longer the priority — even though it remains important for scientific computing, numerical simulation, and other use cases that cannot tolerate reduced precision.
I confirmed that the FP16 path on the 5090 is tensor-core accelerated: an ncu profile of cublasHgemm and cublasGemmEx at 4096×4096 dispatches cutlass_80_tensorop_h16816gemm_... and cutlass_80_tensorop_f16_s16816gemm_... respectively — both tensorop (HMMA 16×8×16), with the SIMT FFMA pipe sitting at <0.2% utilization. So the FP16/BF16 effort is real and visible. The catch: those kernels are also cutlass_80_*-prefixed Ampere forward-ports — Blackwell's incremental tensor-core tuning effort goes into the new low-precision formats (FP8, MXFP4) used by frontier-model training, not into the basic FP16 path. The Ampere kernel reuse on sm_120 isn't unique to the un-loved FP32 SIMT path; it's the dominant pattern across most of cuBLAS's compute paths on Blackwell.
Benchmark Methodology and Other Results
All measurements: 30 iterations (single) or 20 iterations (batched), interleaved with cuBLAS for thermal fairness, first iteration of every loop discarded as warmup, median reported. Compiled with nvcc -O3 --fmad=true (no --use_fast_math — FFMA fusion is preserved but FTZ/relaxed-div are off, so the comparison is IEEE-clean FP32). RTX 5090 (170 SMs, 32 GB GDDR7), driver 595.58.03, CUDA 13.2.51, cuBLAS 13.3.0. The reproducible recipe is in recipes/sgemm_cublas_vs_tma/ — deplodock bench recipes/sgemm_cublas_vs_tma --local.
The 256 / 512 sizes are removed from the single matmul table. At sub-millisecond per-call durations the GPU's boost clock never engages, and the SM clock bounces around for the duration of the run. The bench runner samples nvidia-smi --query-gpu=clocks.sm around each measurement; one full single-batch sweep looks like:
| Size | SM clock (MHz) | Per-call time | Kernel var % |
|---|---|---|---|
| 256 | 260 → 460 | ~8 µs | 84% |
| 512 | 2415 | ~14 µs | 42% |
| 1024 | 2415 | ~50 µs | 6% |
| 2048 | 2415 → 2460 | ~240 µs | 2% |
| 4096 | 2430 → 2415 | ~2 ms | 20% |
| 8192 | 2940 → 2700 | ~17 ms | 25% |
| 16384 | 2940 | ~150 ms | 5% |
The clock is not locked to emulate real-world performance. Since my kernel and cuBLAS are interleaved iteration-by-iteration, the ratio stays meaningful at whatever clock the governor picks at that instant.
The headline tables at the top of this article show the full RTX 5090 sweep; the rest of this section covers other hardware.
RTX PRO 6000 Blackwell (Max-Q)
Same architecture as the 5090 (sm_120) but 188 SMs vs 170 and a lower power budget. Provisioned on CloudRift with the same toolchain (driver 595.58.03 / CUDA 13.2.51) so the comparison is apples-to-apples.
Pro 6000 single matmul:
| Size | TM | BK | KS | Kernel ms | cuBLAS ms | Eff |
|---|---|---|---|---|---|---|
| 1024 | 8 | 32 | 1 | 0.057 | 0.057 | 100% |
| 2048 | 26 | 32 | 1 | 0.304 | 0.316 | 104% |
| 4096 | 26 | 32 | 1 | 2.519 | 2.340 | 93% |
| 8192 | 26 | 32 | 1 | 21.549 | 20.209 | 94% |
| 16384 | 26 | 32 | 1 | 170.773 | 162.355 | 95% |
Pro 6000 batched matmul — note that B=4/8/16 land at ~93–95% (not 150–170% like the 5090) because the Pro 6000 dispatcher actually escalates correctly:
| Size | B=4 | B=8 | B=16 |
|---|---|---|---|
| 256 | 87% | 95% | 77% |
| 512 | 102% | 124% | 101% |
| 1024 | 101% | 104% | 96% |
| 2048 | 90% | 102% | 93% |
| 4096 | 93% | 93% | 93% |
| 8192 | 94% | 95% | 95% |
The 512 / 1024 / 2048 cells where I still beat cuBLAS are the Pro 6000's small-size MAGMA-fallback bug from the dispatcher table. The 4K+ cells are the constant 5–7% generator gap.
H200
TM=8 is optimal at every size on Hopper — larger thread tiles regress, likely because first-gen Hopper TMA has more issue-pressure than Blackwell's refined unit. The H200 is the cleanest control case: when cuBLAS dispatches the right kernel (and on Hopper it always does — see the dispatcher table), my generator loses by the same constant 8–11% as everywhere else.
H200 single matmul:
| Size | TM | BK | KS | Kernel ms | cuBLAS ms | Eff |
|---|---|---|---|---|---|---|
| 1024 | 8 | 32 | 1 | 0.064 | 0.066 | 102% |
| 2048 | 8 | 32 | 1 | 0.396 | 0.348 | 88% |
| 4096 | 8 | 32 | 1 | 3.008 | 2.685 | 89% |
| 8192 | 8 | 32 | 1 | 23.418 | 21.439 | 92% |
| 16384 | 8 | 32 | 1 | 184.515 | 162.931 | 88% |
H200 batched matmul:
| Size | B=4 | B=8 | B=16 |
|---|---|---|---|
| 256 | 85% | 104% | 77% |
| 512 | 105% | 97% | 88% |
| 1024 | 87% | 89% | 89% |
| 2048 | 89% | 90% | 92% |
| 4096 | 91% | 89% | 90% |
| 8192 | 88% | 87% | 87% |
cuBLAS on Hopper hits ~50 TFLOPS across the size range (the H200's HBM3e bandwidth easily feeds the SIMT cores), with FMA pipe utilization climbing from 69% at 512 to 82% at 4K+. My TMA template hits ~47 TFLOPS at 71% FMA pipe util across the range — uniform 8–11% gap to the well-dispatched cuBLAS baseline.
Related Bug Reports
After finding all of this, I went looking for prior reports of cuBLAS picking suboptimal kernels for SGEMM on consumer NVIDIA GPUs. It turns out this isn't a new shape of bug. Substantially similar reports have surfaced at least twice before, both times reported on NVIDIA's developer forums and acknowledged by NVIDIA engineers.
Pascal card is calling Maxwell kernels through cublas. It is unusably slow. (NVIDIA Developer Forums, 2018) — closest match. A user with a GTX 1080 Ti (Pascal sm_61) reported cublasSgemmStridedBatched running maxwell_sgemm_128_64_nn kernels, about 2× slower than a naïve hand-rolled kernel for batched workloads.
cuBLAS sgemm is slow (NVIDIA Developer Forums, 2017). Different shape — extreme aspect ratio, 2×23880 × 23880×32 — but the same root cause: cuBLAS's dispatcher picked a tiny grid [1,1,1] × block [8,8,1], leaving the GPU idle.
vLLM #35467 (2025). vLLM developers report that on certain matmul shapes, "cuBLAS auto-selects the 7th-best tile (128x136) instead of optimal options, with the heuristic leaving 16% performance on the table."
Simon Boehm's CUDA matmul worklog (cited indirectly in many places). Notes the structural fact that "cuBLAS contains not one single implementation of SGEMM, but hundreds of them, and at runtime, based on the dimensions, cuBLAS will pick which kernel to run" — and "cuBLAS may set a too small grid size, which can be identified through profiling tools." Published acknowledgment that the heuristic has known holes.
Conclusion
The headline TMA win on the 5090 turned out to be a cuBLAS dispatcher bug, not a hardware advantage — and, as the Related bug reports section above shows, it's the latest instance of a recurring pattern that NVIDIA has acknowledged on its own developer forums since at least 2018. NVIDIA ships a release version of cuBLAS that, on the most popular consumer Blackwell SKU, picks an FP32 SGEMM kernel running at ~40% of peak FMA pipe utilization for the entire range of batched workloads. The exact same library binary escalates correctly to a 73% kernel on the RTX PRO 6000 and to an 82% kernel on the H200. It's not subtle: the 5090 path picks the wrong kernel 100% of the time across the entire 32× workload range I measured, and the same library has better kernels sitting right there.
I only verified this on the RTX 5090. The dispatch logic is clearly arch-specific, so it would not surprise me if other consumer RTX cards (5070, 5080, 4090, ...) hit similar bugs in their respective dispatch paths. If you have one of those cards, the diagnostic script that surfaced this lives in the repo at scripts/diagnostics/ncu_compare.sh. Three minutes of ncu will tell you whether your batched FP32 workloads are leaving 60% on the floor.
Don't trust cuBLAS blindly on new architectures and or RTX cards. Check kernel name in ncu. If you see something like cutlass_80_simt_sgemm_128x32_8x5 running for a workload that should clearly be on a 256×128 kernel, you're hitting the bug.
Separately, the TMA + compile-time specialization technique is worth knowing for its own sake. It produces a fully pipelined SGEMM kernel template in ~300 lines of generated C that hits ~93% of CUTLASS's hand-tuned peak FMA pipe utilization on every Blackwell SKU I tested. TMA might be useful in many other workloads that leverage conventional CUDA cores.
Links
- Source code: deplodock/compiler/cuda/ — the compiler that generates the kernels
- Benchmark script: scripts/bench_matmul.py — run your own benchmarks
- Reproducible recipe: recipes/sgemm_cublas_vs_tma/ —
deplodock bench recipes/sgemm_cublas_vs_tma --local - Full per-arch dispatch sweep with raw ncu output: recipes/sgemm_cublas_vs_tma/ncu/batched_dispatch_finding.md
- Diagnostic scripts: scripts/diagnostics/ —
dump_cublas_kernels.sh,ncu_compare.sh,cublas_loop_vs_strided.cu,sass_analysis.py - Hardware: RTX 5090 (GB202, sm_120, 32 GB GDDR7, 170 SMs); RTX PRO 6000 Blackwell Max-Q (sm_120, 188 SMs); NVIDIA H200 (GH100, sm_90, 141 GB HBM3e)
- Software: CUDA 13.2.51, nvcc, cuBLAS 13.3.0, Ubuntu 24.04
References
- NVIDIA CUDA Programming Guide — Tensor Memory Access (TMA)
- NVIDIA CUDA Programming Guide — Asynchronous Data Copies
- NVIDIA CUTLASS — SIMT SGEMM reference
- Simon Boehm — How to Optimize a CUDA Matmul Kernel for cuBLAS-like Performance
- Modular — Matrix Multiplication on NVIDIA's Blackwell
- Lei Mao — CUDA Shared Memory Swizzling
- CuAsmRL — SASS Optimization via Reinforcement Learning
- Colfax Research — Efficient GEMM with Pipelining
I write about GPU internals, CUDA optimization, and what happens when you look under the hood of production GPU software. Subscribe to Kernel Space if you want the next deep dive.