A Principled ML Compiler Stack in 5,000 Lines of Python — Part 2

Production ML compilers are intimidating. Half a million lines of C++ in TVM, a tower of Dynamo/Inductor/Triton inside PyTorch, plus XLA, MLIR, Halide, and Mojo. Reading any one of them from top to bottom is a multi-week project.
I took on the task of demystifying the stack by implementing a hackable compiler from scratch. A compiler is reasonably small, with every stage printable on demand and every algorithm reducible to a page of pseudocode.
What came out is a six-IR pipeline that turns a PyTorch graph into a CUDA kernel through a sequence of small, mechanical rewrites:
- Torch IR — the captured FX graph; PyTorch's exact op set.
- Tensor IR — the graph rewritten into three primitive op kinds: elementwise, reduction, and
IndexMap. - Loop IR — primitives lifted to explicit loop nests, then fused into as few kernels as possible.
- Tile IR — loop nests annotated with
THREAD/BLOCKaxis bindings, shared-memoryStages,StridedLoops, and cross-threadCombines. - Kernel IR — Tile IR's scheduling decisions materialized as concrete hardware primitives.
- CUDA — emitted source, ready for
nvcc. A one-to-one tree walk over Kernel IR.
Part 1 took an RMSNorm layer end-to-end and walked the upper half of that pipeline in detail. This second part closes the gap and explains Tile IR, Kernel IR and associated lowering rules in depth. Part 3 lifts the per-rule heuristics introduced here into a search space and adds an SP-MCTS autotuner on top.
On RTX 5090 the emitted FP32 kernels run at geomean 1.11× vs PyTorch eager, 1.20× vs torch.compile, with full-block parity on TinyLlama-128 and Qwen2.5-7B at seq=128. Wins on small reductions / SDPA / kv-projections (up to 4.7×); losses on dense matmul at seq=512. Numbers and per-kernel table in the Validation section.
To follow along, clone the repository (GPU not required for reading the IR; required for the benchmarks at the end):
git clone https://github.com/cloudrift-ai/deplodock.git
cd deplodock && make setup
source venv/bin/activate
This article assumes GPU fluency. If you need a refresher, Simon Boehm's How to Optimize a CUDA Matmul Kernel for cuBLAS-like Performance is the best single piece of writing on the why behind tiling, shared-memory staging, and pipelining — most of what Tile IR mechanizes here.
The week between part 1 and part 2 added ~3,000 lines to the Tile IR stage — so the honest title is closer to "8,192 Lines of Python." However, this extra code helped to close the performance gap with the production stack.
What Tile IR Is
This split between Loop IR and Tile IR mirrors the algorithm/schedule separation from Halide. The Loop IR describes the algorithm as a loop nest. A Tile op wraps the loop nest and carries the launch geometry: which axes are THREAD, which are BLOCK, and additional hardware primitives like smem staging, thread synchronization, etc.
| Loop IR | Tile IR |
|---|---|
|
|
Tile IR Transformation Stack
The whole stack is a sequence of sixteen small rewrite rules, each of which observes some property of the current schedule and refines it. For example, if we see a reduce-like kernel, we rework it to perform an smem-based cooperative tree-reduce.
The stack mimics a sequence of optimization steps a CUDA engineer would perform when optimizing kernels: stage inputs to smem, reduce bank conflicts, increase occupancy, and so on.
LoopOp
│
▼
[001] tileify — lift outer free Loops to thread axes
[002] chunk_matmul_k — chunk the K reduce into K-outer × K-inner (intra-CTA)
[003] split_matmul_k — promote the K-outer chunk loop into a grid dimension
[004] cooperative_reduce — let multiple threads share one reduce; tree-merge with Combine
[005] blockify_launch — pick block extents; partition free axes into BLOCK and THREAD
[006] chunk_reduce — chunk non-matmul reduces so their Loads fit in shared memory
[007] stage_inputs — hoist hot input slabs into Stage nodes
[008] register_tile — replicate the inner tile so each thread owns a register block
[009] permute_register_tile — reorder the register strip so bank-conflicting loads land on far columns
[010] double_buffer — promote K-outer Stages to BufferedStage (ping-pong)
[011] tma_copy — narrow eligible BufferedStages to TmaBufferedStage (sm_90+)
[012] split_inner_for_swizzle — split the inner cache axis of a TmaBufferedStage for swizzle
[013] async_copy — narrow the rest to AsyncBufferedStage (cp.async, sm_80+)
[014] pad_smem — pad shared-memory strides to break bank conflicts
[015] pipeline_k_outer — rotate the K-outer loop into prologue/steady-state/epilogue (cp.async + TMA)
[016] mark_unroll — annotate small inner loops for #pragma unroll
│
▼
TileOp (fully scheduled)
The rest of the post walks through three running examples: a pointwise kernel, a reduction kernel, and a matmul. Rules recognize general kernel shapes and do not require a precise match. For example, RMSNorm and Softmax fall under reduction kernel geometry, even though they perform multiple independent reductions inside them. Thanks to this variability, these three kernel geometries cover almost all kernel types encountered in modern LLMs.
| Example | Compute shape | Rules that fire |
|---|---|---|
Pointwise (GELU on [N, D]) | per-element, no reduce | tileify, blockify_launch, mark_unroll |
Reduction (RMSNorm on [N, D]) | one reduce per row | tileify, cooperative_reduce, stage_inputs |
Matmul (Linear(K, N) on [M, K]) | nested reduce + tiling | the full stack |
Example 1 — Pointwise (GELU)
Pointwise kernels are the simplest case: every output element is independent, there's no reduction, no shared data, no cross-thread coordination. After Loop-IR fusion, GELU on a [32, 18944] input is a single two-deep free-axis loop nest with the whole expression inlined into the body:
deplodock compile \
-c "x=torch.randn(32,18944);0.5*x*(1+torch.tanh(0.797*(x+0.044*x*x*x)))" \
--ir loop
=== 0: merged_mul_5 -> mul_5 ===
for a0 in 0..32: # free
for a1 in 0..18944: # free
in4 = load x[a0, a1]
v0 = multiply(in4, 0.044)
v1 = multiply(v0, in4)
v2 = multiply(v1, in4)
v3 = add(in4, v2)
v4 = multiply(v3, 0.797)
v5 = tanh(v4)
v6 = add(v5, 1)
v7 = multiply(in4, 0.5)
v8 = multiply(v7, v6)
merged_mul_5[a0, a1] = v8
This is the input to the tile pass. Running the full lowering with -vv emits one block per rule application: a unified diff between the matched body before and after the rewrite, bracketed by >>> t: and <<< t: markers (t stands for Tile IR). Skipped rules collapse to one-liners starting with --- t:. Filtering for just the headers gives a one-glance summary of which rules fired:
deplodock compile \
-c "x=torch.randn(32,18944);0.5*x*(1+torch.tanh(0.797*(x+0.044*x*x*x)))" \
--ir tile -vv \
| grep -E '^>>> t:|^--- t:'
>>> t:001_tileify
--- t:002_chunk_matmul_k skipped at mul_5: no matmul-shaped reduce Loop with K-divisor in candidates
--- t:003_split_matmul_k skipped at mul_5: no chunked matmul Loop in tile body
--- t:004_cooperative_reduce skipped at mul_5: Tile body has no reduce Loop
>>> t:005_blockify_launch
--- t:006_chunk_reduce skipped at mul_5: no non-matmul reduce Loop with stage-eligible fan-in needs chunking
--- t:007_stage_inputs skipped at mul_5: no Load qualifies for staging
--- t:008_register_tile skipped at mul_5: no matmul-shaped reduce in the Tile body — register tiling unprofitable
--- t:009_permute_register_tile skipped at mul_5: need >=2 THREAD axes (matmul-shaped tile)
--- t:010_double_buffer skipped at mul_5: no K-outer matmul Loop eligible for double-buffering within smem budget
--- t:011_tma_copy skipped at mul_5: no BufferedStage to convert
--- t:012_split_inner_for_swizzle skipped at mul_5: DEPLODOCK_TMA_SWIZZLE not set
--- t:013_async_copy skipped at mul_5: no Stage eligible for cp.async (need >= 16 bytes/thread)
--- t:014_pad_smem skipped at mul_5: no Stage has a fixable bank conflict within slab budget
--- t:015_pipeline_k_outer skipped at mul_5: no eligible K-outer Loop with AsyncBufferedStage loads to pipeline
--- t:016_mark_unroll skipped at mul_5: no Loop nest with total trips <= 64 found
Every skip reason is a one-line statement of why the rule's pattern didn't match: no reduce Loop in the body (rules 4, 8), no matmul-shaped reduce (rules 2, 3, 8), no BufferedStage for the transports to narrow (rules 11, 12, 13, 14, 15), no Loads worth staging (rule 7).
Tileify
The tileify rule is a mouthful, but it is the simplest rule in the stack. It strips every outer free Loop, lifting it to the surrounding tile's thread axes. Just a structural relabeling that says "these axes are parallel". Body stays intact.
deplodock compile \
-c "x=torch.randn(32,18944);0.5*x*(1+torch.tanh(0.797*(x+0.044*x*x*x)))" \
--ir tile -vv \
| awk '/^>>> t:001/,/^<<< t:001/'
>>> t:001_tileify
@@ matched at merged_merged_merged_lift_mul_5 (in-place) @@
@@ -1,14 +1,13 @@
-mul_5 = LoopOp(mul_1_c1, mul_4_c1, add_1_c1, mul_c1, x)
- for a0 in 0..32: # free
- for a1 in 0..18944: # free
- in4 = load x[a0, a1]
- v0 = multiply(in4, 0.044)
- v1 = multiply(v0, in4)
- v2 = multiply(v1, in4)
- v3 = add(in4, v2)
- v4 = multiply(v3, 0.797)
- v5 = tanh(v4)
- v6 = add(v5, 1)
- v7 = multiply(in4, 0.5)
- v8 = multiply(v7, v6)
- merged_merged_merged_lift_mul_5[a0, a1] = v8
+mul_5 = TileOp(mul_1_c1, mul_4_c1, add_1_c1, mul_c1, x)
+ Tile(axes=(a0:32=THREAD, a1:18944=THREAD)):
+ in4 = load x[a0, a1]
+ v0 = multiply(in4, 0.044)
+ v1 = multiply(v0, in4)
+ v2 = multiply(v1, in4)
+ v3 = add(in4, v2)
+ v4 = multiply(v3, 0.797)
+ v5 = tanh(v4)
+ v6 = add(v5, 1)
+ v7 = multiply(in4, 0.5)
+ v8 = multiply(v7, v6)
+ mul_5[a0, a1] = v8
<<< t:001_tileify
Blockify Launch
The blockify_launch rule partitions the thread axes into BLOCK and THREAD based on a target threads-per-block (256 here) and the axis extents. For GELU it splits the inner axis (18944 = 74 × 256).
deplodock compile \
-c "x=torch.randn(32,18944);0.5*x*(1+torch.tanh(0.797*(x+0.044*x*x*x)))" \
--ir tile -vv \
| awk '/^>>> t:005/,/^<<< t:005/'
>>> t:005_blockify_launch
@@ matched at mul_5 (in-place) @@
@@ -1,5 +1,5 @@
mul_5 = TileOp(mul_1_c1, mul_4_c1, add_1_c1, mul_c1, x)
- Tile(axes=(a0:32=THREAD, a1:18944=THREAD)):
- in4 = load x[a0, a1]
+ Tile(axes=(a0:32=BLOCK, a1:74=BLOCK, a2:256=THREAD)):
+ in4 = load x[a0, ((a1 * 256) + a2)]
v0 = multiply(in4, 0.044)
v1 = multiply(v0, in4)
@@ -11,3 +11,3 @@
v7 = multiply(in4, 0.5)
v8 = multiply(v7, v6)
- mul_5[a0, a1] = v8
+ mul_5[a0, ((a1 * 256) + a2)] = v8
<<< t:005_blockify_launch
Outer axis a0 (the 32 batch rows) flips THREAD → BLOCK. The 18944-column axis is split into a BLOCK factor of 74 over a THREAD factor of 256. The x[a0, a1] Load and the output Store pick up the recomposed index [a0, a1*256 + a2].
That's the entire schedule for a pointwise kernel: 32 × 74 = 2368 blocks, 256 threads each, every thread does one HBM read, one HBM write, and the seven-op GELU expression in registers in between.
Final CUDA
The two rules above lower all the way through Kernel IR and CUDA emission with no further structural changes.
deplodock compile \
-c "x=torch.randn(32,18944);0.5*x*(1+torch.tanh(0.797*(x+0.044*x*x*x)))" \
--target sm_120 --ir cuda
extern "C" __global__
__launch_bounds__(256) void k_mul_5_pointwise(const float* x, float* mul_5) {
int a0 = blockIdx.x / 74;
int a1 = blockIdx.x % 74;
int a2 = threadIdx.x;
float in4 = x[a0 * 18944 + (a1 * 256 + a2)];
float v0 = in4 * 0.044f;
float v1 = v0 * in4;
float v2 = v1 * in4;
float v3 = in4 + v2;
float v4 = v3 * 0.797f;
float v5 = tanhf(v4);
float v6 = v5 + 1.0f;
float v7 = in4 * 0.5f;
float v8 = v7 * v6;
mul_5[a0 * 18944 + (a1 * 256 + a2)] = v8;
}
One HBM load, one HBM store, the seven-op expression in between — exactly what tileify + blockify_launch promised at the IR level.
Example 2 — Reduction (RMSNorm)
RMSNorm is the canonical reduction shape: one reduce per row of the input. The Loop IR has an outer free axis (rows), an inner reduce sweep that computes the row's mean-square, a scalar rsqrt, and a second free sweep that writes the normalized row.
deplodock compile \
-c "torch.nn.RMSNorm(2048)(torch.randn(1,32,2048))" \
--ir loop
=== 0: merged_n0 -> rms_norm ===
v0 = reciprocal(2048)
for a0 in 0..32: # free
for a1 in 0..2048: # reduce
in2 = load x[0, a0, a1]
v1 = multiply(in2, in2)
acc0 <- add(acc0, v1)
v2 = multiply(acc0, v0)
v3 = add(v2, 1e-06)
v4 = rsqrt(v3)
for a2 in 0..2048: # free
in3 = load x[0, a0, a2]
in4 = load p_weight[a2]
v5 = multiply(in3, v4)
v6 = multiply(v5, in4)
merged_n0[0, a0, a2] = v6
The rule trace through the tile pass picks up cooperative_reduce and stage_inputs over what GELU fired.
deplodock compile \
-c "torch.nn.RMSNorm(2048)(torch.randn(1,32,2048))" \
--ir tile -vv \
| grep -E '^>>> t:|^--- t:'
>>> t:001_tileify
--- t:002_chunk_matmul_k skipped at rms_norm: no matmul-shaped reduce Loop with K-divisor in candidates
--- t:003_split_matmul_k skipped at rms_norm: no chunked matmul Loop in tile body
>>> t:004_cooperative_reduce
--- t:005_blockify_launch skipped at rms_norm: Tile already partitioned (block_axes non-empty)
--- t:006_chunk_reduce skipped at rms_norm: no non-matmul reduce Loop with stage-eligible fan-in needs chunking
>>> t:007_stage_inputs
--- t:008_register_tile skipped at rms_norm: no matmul-shaped reduce in the Tile body — register tiling unprofitable
--- t:009_permute_register_tile skipped at rms_norm: need >=2 THREAD axes (matmul-shaped tile)
--- t:010_double_buffer skipped at rms_norm: no K-outer matmul Loop eligible for double-buffering within smem budget
--- t:011_tma_copy skipped at rms_norm: no BufferedStage to convert
--- t:012_split_inner_for_swizzle skipped at rms_norm: DEPLODOCK_TMA_SWIZZLE not set
--- t:013_async_copy skipped at rms_norm: no Stage eligible for cp.async (need >= 16 bytes/thread)
--- t:014_pad_smem skipped at rms_norm: no Stage has a fixable bank conflict within slab budget
--- t:015_pipeline_k_outer skipped at rms_norm: no eligible K-outer Loop with AsyncBufferedStage loads to pipeline
--- t:016_mark_unroll skipped at rms_norm: no Loop nest with total trips <= 64 found
Tileify
Same as before: the outer free row axis is lifted to a thread axis on the surrounding Tile. The reduce sweep and the second free sweep stay in the body — they are not the outer free chain. With both reduces still serialized inside one thread, the initial Tile axes are (a0:32=THREAD, a1:2048=THREAD):
>>> t:001_tileify
@@ matched at merged_merged_merged_lift_n0 (in-place) @@
@@ -1,7 +1,7 @@
-rms_norm = LoopOp(rms_norm_mean_count, rms_norm_eps, x, p_weight)
+rms_norm = TileOp(rms_norm_mean_count, rms_norm_eps, x, p_weight)
v0 = reciprocal(2048)
- for a0 in 0..32: # free
- for a1 in 0..2048: # reduce
- in2 = load x[0, a0, a1]
+ Tile(axes=(a0:32=THREAD, a1:2048=THREAD)):
+ for a2 in 0..2048: # reduce
+ in2 = load x[0, a0, a2]
v1 = multiply(in2, in2)
acc0 <- add(acc0, v1)
@@ -9,8 +9,7 @@
v3 = add(v2, 1e-06)
v4 = rsqrt(v3)
- for a2 in 0..2048: # free
- in3 = load x[0, a0, a2]
- in4 = load p_weight[a2]
- v5 = multiply(in3, v4)
- v6 = multiply(v5, in4)
- merged_merged_merged_lift_n0[0, a0, a2] = v6
+ in3 = load x[0, a0, a1]
+ in4 = load p_weight[a1]
+ v5 = multiply(in3, v4)
+ v6 = multiply(v5, in4)
+ rms_norm[0, a0, a1] = v6
<<< t:001_tileify
Note that v0 = reciprocal(2048) (a tile-scope precompute) and the inner reduce loop both stay where they were — they're inside the body, not on the outer free chain that tileify peeled off.
Cooperative Reduce
This is the first rule the pointwise example skipped. RMSNorm's reduce sweep is 2048 elements long; if a single thread did it serially, the other threads in the block would sit idle for the whole reduce. cooperative_reduce rewrites the reduce axis into a StridedLoop plus a Combine:
- each of
Tthreads walks2048 / Tindices, accumulating a partial in a register; - a
Combine(acc, op=add)tree-merges the partials across threads through shared memory.
deplodock compile \
-c "torch.nn.RMSNorm(2048)(torch.randn(1,32,2048))" \
--ir tile -vv \
| awk '/^>>> t:004/,/^<<< t:004/'
The first thing to look at is the new launch geometry on the tile:
>>> t:004_cooperative_reduce
@@ matched at rms_norm (in-place) @@
rms_norm = TileOp(rms_norm_mean_count, rms_norm_eps, x, p_weight)
v0 = reciprocal(2048)
- Tile(axes=(a0:32=THREAD, a1:2048=THREAD)):
+ Tile(axes=(a0:256=THREAD, a1:32=BLOCK)):
The 32-row outer axis flips THREAD → BLOCK (one CTA per row, 32 CTAs total), and the 2048-wide row axis is gone from the thread axes — replaced by a fresh 256-thread cooperating axis. That's the launch decision: 256 threads will share the work on each row instead of one thread doing it serially.
Once the row axis is no longer a thread axis, every sweep that walks the row has to walk cooperatively. The reduce gets the canonical strided pattern + a tree merge:
- for a2 in 0..2048: # reduce
- in2 = load x[0, a0, a2]
+ StridedLoop(a2 = a0; < 2048; += 256): # reduce
+ in2 = load x[0, a1, a2]
v1 = multiply(in2, in2)
acc0 <- add(acc0, v1)
+ Combine(acc0, op=add)
Each thread starts at its lane id a0 and steps by 256, so thread 0 visits columns 0, 256, 512, …, 1792, thread 1 visits 1, 257, …, etc. After the loop every thread holds a partial sum of 2048 / 256 = 8 squared elements; Combine(acc0, op=add) tree-merges the 256 partials through shared memory into a single block-wide accumulator.
The epilogue free sweep that writes the normalized row gets the same cooperative-strided treatment, for the same reason — the row width no longer matches the thread count, so writing element-per-thread isn't an option:
Since a1 axis now sweeps from 0..256 instead of 2048, the epilogue is rewritten so each thread produces eight output elements via the same strided pattern — thread a0 writes columns a0, a0+256, a0+512, ....
- v2 = multiply(acc0, v0)
- v3 = add(v2, 1e-06)
- v4 = rsqrt(v3)
- in3 = load x[0, a0, a1]
- in4 = load p_weight[a1]
- v5 = multiply(in3, v4)
- v6 = multiply(v5, in4)
- rms_norm[0, a0, a1] = v6
+ StridedLoop(a2 = a0; < 2048; += 256): # free
+ in3 = load x[0, a1, a2]
+ in4 = load p_weight[a2]
+ v5 = multiply(in3, v4)
+ v6 = multiply(v5, in4)
+ rms_norm[0, a1, a2] = v6
<<< t:004_cooperative_reduce
The general rule: any free or reduce sweep whose extent matches the original row-thread axis has to be rewritten to a StridedLoop over the new cooperative axis. The same rewrite handles softmax's three sweeps the same way (online stats reduce, mean reduce, normalized write) — RMSNorm just happens to have one.
Stage Inputs
The same row of x is read twice: once by the mean-square reduce, once by the write sweep, so it will benefit from staging into smem.
deplodock compile \
-c "torch.nn.RMSNorm(2048)(torch.randn(1,32,2048))" \
--ir tile -vv \
| awk '/^>>> t:007/,/^<<< t:007/'
>>> t:007_stage_inputs
@@ matched at rms_norm (in-place) @@
@@ -2,6 +2,7 @@
v0 = reciprocal(2048)
Tile(axes=(a0:256=THREAD, a1:32=BLOCK)):
+ x_smem = Stage(x, origin=(0, a1, 0), slab=(a2:2048@2))
StridedLoop(a2 = a0; < 2048; += 256): # reduce
- in2 = load x[0, a1, a2]
+ in2 = load x_smem[a2]
v1 = multiply(in2, in2)
acc0 <- add(acc0, v1)
@@ -11,5 +12,5 @@
v4 = rsqrt(v3)
StridedLoop(a2 = a0; < 2048; += 256): # free
- in3 = load x[0, a1, a2]
+ in3 = load x_smem[a2]
in4 = load p_weight[a2]
v5 = multiply(in3, v4)
<<< t:007_stage_inputs
A single Stage node for x appears at the top of the tile body — both consumers of the row (the reduce sweep and the normalized-write sweep) share it — and the corresponding Loads in the body switch over to read from the staged buffer. The p_weight Load is left untouched: at seq_len=32, the per-row p_weight reuse is small enough that staging doesn't pay back the smem cost. The Stage carries an origin= (where in HBM the slab starts, parameterized by the surrounding axes) and a slab= shape with per-axis ownership annotations (@2 = strided across threads of axis a0, @0 = broadcast).
The optional chunk_reduce rule fires when the post-blockify reduce slab would exceed stage_inputs's 16 KB shared-memory cap. The 2048-wide row at fp32 is 8 KB — fits — so chunk_reduce is a no-op. (At seq-length 16384 it would fire and chunk the row.)
Final CUDA
For a reduction kernel, lowering picks up two extra rules over the pointwise case: cooperative_reduce and stage_inputs (plus chunk_reduce at long seq-len). The result is 32 blocks × 256 threads, the row staged into shared memory, a warp-shuffle reduction folded into a block-level tree merge through a tiny acc0_smem[8] staging buffer, then a strided cooperative write:
deplodock compile \
-c "torch.nn.RMSNorm(2048)(torch.randn(1,32,2048))" \
--target sm_120 --ir cuda
extern "C" __global__
__launch_bounds__(256) void k_rms_norm_reduce(
const float* x, const float* p_weight, float* rms_norm) {
float v0 = 1.0f / 2048.0f;
int a1 = blockIdx.x;
int a0 = threadIdx.x;
int lane = threadIdx.x & 31;
int warp = threadIdx.x >> 5;
float acc0 = 0.0f;
__shared__ float x_smem[2048];
for (int x_smem_flat = a0; x_smem_flat < 2048; x_smem_flat += 256) {
float x_smem_v = x[a1 * 2048 + x_smem_flat];
x_smem[x_smem_flat] = x_smem_v;
}
__syncthreads();
for (int a2 = a0; a2 < 2048; a2 += 256) {
float in2 = x_smem[a2];
float v1 = in2 * in2;
acc0 += v1;
}
float acc0_w = acc0;
acc0_w = acc0_w + __shfl_xor_sync(0xffffffff, acc0_w, 16);
acc0_w = acc0_w + __shfl_xor_sync(0xffffffff, acc0_w, 8);
acc0_w = acc0_w + __shfl_xor_sync(0xffffffff, acc0_w, 4);
acc0_w = acc0_w + __shfl_xor_sync(0xffffffff, acc0_w, 2);
acc0_w = acc0_w + __shfl_xor_sync(0xffffffff, acc0_w, 1);
__shared__ float acc0_smem[8];
if (lane == 0) {
acc0_smem[warp] = acc0_w;
}
__syncthreads();
for (int s = 4; s > 0; s >>= 1) {
if (warp < s) {
acc0_smem[warp] = acc0_smem[warp] + acc0_smem[warp + s];
}
__syncthreads();
}
float acc0_b = acc0_smem[0];
float v2 = acc0_b * v0;
float v3 = v2 + 1e-06f;
float v4 = rsqrtf(v3);
for (int a2 = a0; a2 < 2048; a2 += 256) {
float in3 = x_smem[a2];
float in4 = p_weight[a2];
float v5 = in3 * v4;
float v6 = v5 * in4;
rms_norm[a1 * 2048 + a2] = v6;
}
}
The same pattern (cooperative reduce + staging) covers softmax, layernorm, and the per-row sweeps inside SDPA without any kernel-specific code.
Example 3 — Matmul
Matmul is the case that exercises the entire stack. Matmul accounts for the largest chunk of the compute budget, so most of the rules in the stack are designed to optimize it.
deplodock compile \
-c "torch.nn.Linear(3584,3584,bias=False)(torch.randn(512,3584))" \
--ir loop
=== 0: merged_n0 -> linear ===
for a0 in 0..512: # free
for a1 in 0..3584: # free
for a2 in 0..3584: # reduce
in0 = load n1[a2, a1]
in1 = load input[a0, a2]
v0 = multiply(in1, in0)
acc0 <- add(acc0, v0)
merged_n0[a0, a1] = acc0
The rule trace through the tile pass for this matmul fires almost everything in the stack:
deplodock compile \
-c "torch.nn.Linear(3584,3584,bias=False)(torch.randn(512,3584))" \
--ir tile -vv \
| grep -E '^>>> t:|^--- t:'
>>> t:001_tileify
>>> t:002_chunk_matmul_k
>>> t:003_split_matmul_k
--- t:004_cooperative_reduce skipped at linear: Tile body has no reduce Loop
>>> t:005_blockify_launch
--- t:006_chunk_reduce skipped at linear: no non-matmul reduce Loop with stage-eligible fan-in needs chunking
>>> t:007_stage_inputs
>>> t:008_register_tile
>>> t:009_permute_register_tile
>>> t:010_double_buffer
>>> t:011_tma_copy
--- t:012_split_inner_for_swizzle skipped at linear: DEPLODOCK_TMA_SWIZZLE not set
--- t:013_async_copy skipped at linear: no Stage eligible for cp.async (need >= 16 bytes/thread)
--- t:014_pad_smem skipped at linear: no Stage has a fixable bank conflict within slab budget
>>> t:015_pipeline_k_outer
>>> t:016_mark_unroll
All snippets below default to the sm_120 lowering path (Blackwell, the architecture this compiler is most exercised on); pass --target sm_80 or --target sm_90 to see how the transport choice changes downstream.
Tileify
The outer M and N free Loops are lifted into thread axes; the K reduce stays in the body. Same structural rewrite as in the GELU and RMSNorm examples.
deplodock compile \
-c "torch.nn.Linear(3584,3584,bias=False)(torch.randn(512,3584))" \
--target sm_120 --ir tile -vv \
| awk '/^>>> t:001/,/^<<< t:001/'
>>> t:001_tileify
@@ matched at merged_merged_lift_n0 (in-place) @@
@@ -1,9 +1,8 @@
-linear = LoopOp(linear_wt, input)
- for a0 in 0..512: # free
- for a1 in 0..3584: # free
- for a2 in 0..3584: # reduce
- in0 = load n1[a2, a1]
- in1 = load input[a0, a2]
- v0 = multiply(in1, in0)
- acc0 <- add(acc0, v0)
- merged_merged_lift_n0[a0, a1] = acc0
+linear = TileOp(linear_wt, input)
+ Tile(axes=(a0:512=THREAD, a1:3584=THREAD)):
+ for a2 in 0..3584: # reduce
+ in0 = load n1[a2, a1]
+ in1 = load input[a0, a2]
+ v0 = multiply(in1, in0)
+ acc0 <- add(acc0, v0)
+ linear[a0, a1] = acc0
<<< t:001_tileify
The K reduce stays in the body — it's not on the outer free chain. Everything that follows is about giving that K reduce, and the surrounding tile, a sensible launch geometry.
Chunk Matmul K
The K reduce is one big loop of length 3584 — too long for a single thread to keep in registers, and structurally wrong for staging (you can't fit a 3584-element slab of A and B in shared memory). chunk_matmul_k chunks it into nested K-outer × K-inner, with K-inner sized to fit the eventual stage budget (16 here):
deplodock compile \
-c "torch.nn.Linear(3584,3584,bias=False)(torch.randn(512,3584))" \
--ir tile -vv \
| awk '/^>>> t:002/,/^<<< t:002/'
>>> t:002_chunk_matmul_k
@@ matched at linear (in-place) @@
@@ -1,8 +1,9 @@
linear = TileOp(linear_wt, input)
Tile(axes=(a0:512=THREAD, a1:3584=THREAD)):
- for a2 in 0..3584: # reduce
- in0 = load n1[a2, a1]
- in1 = load input[a0, a2]
- v0 = multiply(in1, in0)
- acc0 <- add(acc0, v0)
+ for a2 in 0..224: # free
+ for a3 in 0..16: # reduce
+ in0 = load n1[((a2 * 16) + a3), a1]
+ in1 = load input[a0, ((a2 * 16) + a3)]
+ v0 = multiply(in1, in0)
+ acc0 <- add(acc0, v0)
linear[a0, a1] = acc0
<<< t:002_chunk_matmul_k
This is the rewrite that creates the staging boundary: every subsequent shared-memory pass operates on the K-inner slab, and the K-outer loop walks across slabs.
Split Matmul K
This is the canonical split-K from CUTLASS / cuBLAS / Triton: for matmuls where the natural (M, N) grid doesn't fill the device, split_matmul_k promotes the K-outer chunk loop (created by chunk_matmul_k in the prior step) into a grid dimension. Each CTA computes a partial sum over its K-outer chunks, and an atomic-add (or epilogue kernel) reduces across CTAs.
For the running Linear(3584, 3584) at M=512 the natural grid already saturates the SMs, so this pass does nothing on that shape. To trigger it, drop to a Qwen-style k/v projection at small batch, e.g. Linear(3584, 512) on [32, 3584] produces a (32, 512) output grid that's far too small to fill an SM-rich device.
deplodock compile \
-c "torch.nn.Linear(3584,512,bias=False)(torch.randn(32,3584))" \
--target sm_120 --ir tile -vv \
| awk '/^>>> t:003/,/^<<< t:003/'
>>> t:003_split_matmul_k
@@ matched at linear (in-place) @@
@@ -1,9 +1,9 @@
linear = TileOp(linear_wt, input)
- Tile(axes=(a0:32=THREAD, a1:512=THREAD)):
- for a2 in 0..112: # free
- for a3 in 0..32: # reduce
- in0 = load n1[((a2 * 32) + a3), a1]
- in1 = load input[a0, ((a2 * 32) + a3)]
+ Tile(axes=(a0:28=THREAD, a1:32=THREAD, a2:512=THREAD)):
+ for a3 in 0..4: # free
+ for a4 in 0..32: # reduce
+ in0 = load n1[((((a0 * 4) + a3) * 32) + a4), a2]
+ in1 = load input[a1, ((((a0 * 4) + a3) * 32) + a4)]
v0 = multiply(in1, in0)
acc0 <- add(acc0, v0)
- linear[a0, a1] = acc0
+ linear[a1, a2] += acc0
<<< t:003_split_matmul_k
Two structural changes. First, the 112-iteration K-outer chunk loop (for a2 in 0..112: # free) is split: a 28-way slice is hoisted to the leading thread axis a0:28=THREAD (the split-K grid factor), with a 4-iteration tail for a3 in 0..4: # free left in the body so each CTA still walks four K-inner chunks. Second, the output Write changes from = to += — every CTA now contributes a partial sum, so the codegen will emit an atomic-add.
Epilogue Treatment
In a real fused graph, the loop body usually has some extra operations: a scale, a residual add, and an activation. Whether split_matmul_k can fire depends on whether that epilogue is linear in the accumulator.
Case 1 — multiplicative scale (distributes). A common post-fusion shape is the SwiGLU down-projection, where the up/gate branch's elementwise output multiplies the accumulator before it's stored: out = (down @ x) * silu(gate). After fusion, the gate value lives in a Stage, and the multiply lands inside the matmul TileOp, between the K-outer Loop and the Write:
Tile(axes=(a0:32=THREAD, a1:512=THREAD)):
- for a2 in 0..112: # free
- for a3 in 0..32: # reduce
- …
- acc0 <- add(acc0, v0)
- v_scale = multiply(acc0, gate_silu)
- out[a0, a1] = v_scale
+Tile(axes=(a0:112=THREAD, a1:32=THREAD, a2:512=THREAD)):
+ for a3 in 0..32: # reduce
+ …
+ acc0 <- add(acc0, v0)
+ v_scale = multiply(acc0, gate_silu)
+ out[a1, a2] += v_scale
The Σₖ (c · accₖ) = c · Σₖ accₖ — every CTA computes its own c · partial_acc and atomic-adds into the same output cell. Any chain of multiply ops where each step has exactly one acc-dependent operand is accepted (so acc * a * b * c is fine, acc * acc is not).
Case 2 — additive residual (one CTA adds the bias). Residual streams in transformer blocks fuse the same way: out = (down @ x) + residual. The add is linear, but it doesn't distribute across CTAs — Σₖ (accₖ + r) ≠ (Σₖ accₖ) + r unless exactly one CTA contributes r. The rewrite splits the Write in two: every CTA atomic-adds its accumulator, and a Cond(K_split == 0, ...) lands the residual once.
Tile(axes=(a0:32=THREAD, a1:512=THREAD)):
- for a2 in 0..112: # free
- for a3 in 0..32: # reduce
- …
- acc0 <- add(acc0, v0)
- r = load residual[a0, a1] # epilogue-position Load
- v_sum = add(acc0, r)
- out[a0, a1] = v_sum
+Tile(axes=(a0:112=THREAD, a1:32=THREAD, a2:512=THREAD)):
+ for a3 in 0..32: # reduce
+ …
+ acc0 <- add(acc0, v0)
+ out[a1, a2] += acc0 # every CTA contributes its partial
+ if a0 == 0:
+ r = load residual[a1, a2] # Load moves into the Cond body
+ out[a1, a2] += r
Case 3 — non-linear epilogue (refused). Activations baked into the matmul body block the split. Imagine the same matmul with a ReLU before the Write:
Tile(axes=(a0:32=THREAD, a1:512=THREAD)):
for a2 in 0..112: # free
for a3 in 0..32: # reduce
…
acc0 <- add(acc0, v0)
v_act = relu(acc0)
out[a0, a1] = v_act
relu(Σₖ accₖ) ≠ Σₖ relu(accₖ), so no per-CTA partial is meaningful — the activation has to see the fully reduced sum. The pass logs epilogue isn't a split-K-safe shape and skips, leaving the K-outer chunk loop sequential inside one CTA.
Blockify Launch
The M and N free thread axes are partitioned into a BLOCK × THREAD mix that targets ~256 threads-per-block (actual dimensions are determined by tunable heuristic). The K-outer chunk loop also gets sliced into a block factor so the natural grid covers the device, and the Loads pick up the recomposed indices:
deplodock compile \
-c "torch.nn.Linear(3584,3584,bias=False)(torch.randn(512,3584))" \
--target sm_120 --ir tile -vv \
| awk '/^>>> t:005/,/^<<< t:005/'
>>> t:005_blockify_launch
@@ matched at linear (in-place) @@
@@ -1,9 +1,9 @@
linear = TileOp(linear_wt, input)
- Tile(axes=(a0:4=THREAD, a1:512=THREAD, a2:3584=THREAD)):
- for a3 in 0..56: # free
- for a4 in 0..16: # reduce
- in0 = load n1[((((a0 * 56) + a3) * 16) + a4), a2]
- in1 = load input[a1, ((((a0 * 56) + a3) * 16) + a4)]
+ Tile(axes=(a0:4=BLOCK, a1:8=BLOCK, a2:64=THREAD, a3:28=BLOCK, a4:128=THREAD)):
+ for a5 in 0..56: # free
+ for a6 in 0..16: # reduce
+ in0 = load n1[((((a0 * 56) + a5) * 16) + a6), ((a3 * 128) + a4)]
+ in1 = load input[((a1 * 64) + a2), ((((a0 * 56) + a5) * 16) + a6)]
v0 = multiply(in1, in0)
acc0 <- add(acc0, v0)
- linear[a1, a2] += acc0
+ linear[((a1 * 64) + a2), ((a3 * 128) + a4)] += acc0
<<< t:005_blockify_launch
Total grid: 4 × 8 × 28 = 896 CTAs, which saturates the SMs on a Blackwell device. The body's [a1, a2] and [..., a2] indices get recomposed to [a1*64 + a2, a3*128 + a4].
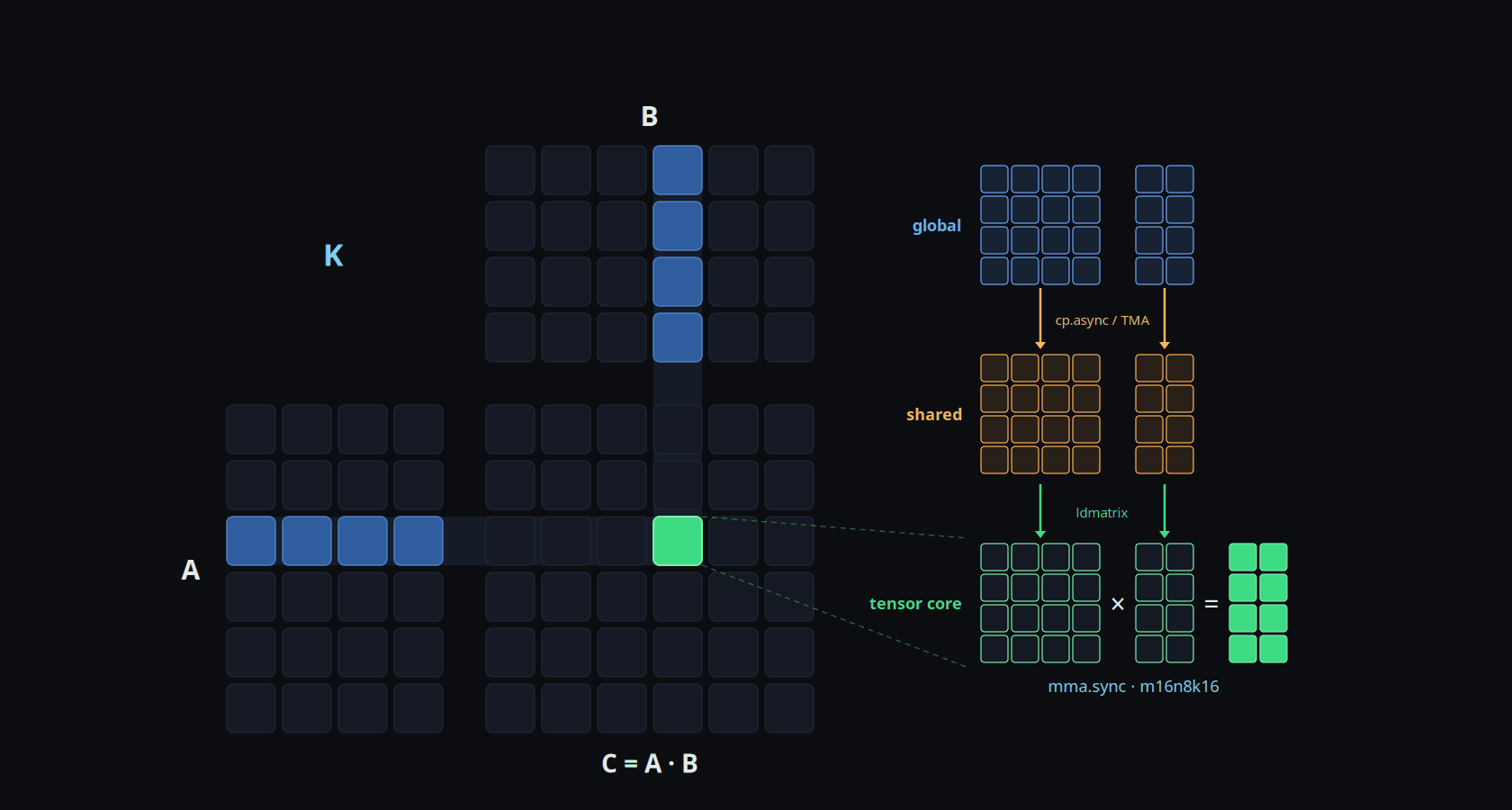
Stage Inputs
The p_weight slab and the input slab are both reused across every thread's inner accumulation, so both are hoisted to Stage nodes inside the K-outer loop. Every K-outer iteration cooperatively fills both Stages and then runs the K-inner inner product against them.
deplodock compile \
-c "torch.nn.Linear(3584,3584,bias=False)(torch.randn(512,3584))" \
--ir tile -vv \
| awk '/^>>> t:007/,/^<<< t:007/'
>>> t:007_stage_inputs
@@ matched at linear (in-place) @@
@@ -2,7 +2,9 @@
Tile(axes=(a0:4=BLOCK, a1:8=BLOCK, a2:64=THREAD, a3:28=BLOCK, a4:128=THREAD)):
for a5 in 0..56: # free
+ n1_smem = Stage(n1, origin=((((a0 * 56) + a5) * 16), (a3 * 128)), slab=(a6:16@0, a4:128@1))
+ input_smem = Stage(input, origin=((a1 * 64), (((a0 * 56) + a5) * 16)), slab=(a2:64@0, a6:16@1))
for a6 in 0..16: # reduce
- in0 = load n1[((((a0 * 56) + a5) * 16) + a6), ((a3 * 128) + a4)]
- in1 = load input[((a1 * 64) + a2), ((((a0 * 56) + a5) * 16) + a6)]
+ in0 = load n1_smem[a6, a4]
+ in1 = load input_smem[a2, a6]
v0 = multiply(in1, in0)
acc0 <- add(acc0, v0)
<<< t:007_stage_inputs
Register Tile
Even with staging, one output per thread leaves an order-of-magnitude gap in arithmetic intensity: each K-inner iteration costs two SMEM loads per FMA, or 0.5 flop/load. Promoting each thread to compute an F_M × F_N register block reuses the same F_M + F_N smem loads to drive F_M × F_N FMAs, so the ratio jumps as the tile grows (4×4 → 2.0 flop/load, 8×4 → 2.7, 8×8 → 4.0). This is the classic register-tiling argument from Volkov's Better Performance at Lower Occupancy.
The pass picks the tile size based on the M and N extents and the available register budget. Too small → bandwidth-bound on shared memory. Too large → register spills. Both extremes are expensive. The default is (F_M, F_N) = (8, 4). Those knobs are overridable via DEPLODOCK_FM / DEPLODOCK_FN, thus for the rest of this section, I override to (F_M, F_N) = (2, 2) (4 outputs / thread) so the diffs and the final CUDA listing stay readable.
DEPLODOCK_FM=2 DEPLODOCK_FN=2 deplodock compile \
-c "torch.nn.Linear(3584,3584,bias=False)(torch.randn(512,3584))" \
--target sm_120 --ir tile -vv \
| awk '/^>>> t:008/,/^<<< t:008/'
>>> t:008_register_tile
@@ matched at linear (in-place) @@
- Tile(axes=(a0:4=BLOCK, a1:8=BLOCK, a2:64=THREAD, a3:28=BLOCK, a4:128=THREAD)):
+ Tile(axes=(a0:4=BLOCK, a1:8=BLOCK, a2:32=THREAD, a3:28=BLOCK, a4:64=THREAD)):
for a5 in 0..56: # free
n1_smem = Stage(n1, ...) # singleton, unchanged
input_smem = Stage(input, ...)
for a6 in 0..16: # reduce
- in0 = load n1_smem[a6, a4]
- in1 = load input_smem[a2, a6]
- v0 = multiply(in1, in0)
- acc0 <- add(acc0, v0)
+ in0 = load n1_smem[a6, (a4 * 2)]
+ in1 = load n1_smem[a6, ((a4 * 2) + 1)]
+ in2 = load input_smem[(a2 * 2), a6]
+ in3 = load input_smem[((a2 * 2) + 1), a6]
+ v0 = multiply(in2, in0)
+ v1 = multiply(in2, in1)
+ v2 = multiply(in3, in0)
+ v3 = multiply(in3, in1)
+ acc0 <- add(acc0, v0)
+ acc1 <- add(acc1, v1)
+ acc2 <- add(acc2, v2)
+ acc3 <- add(acc3, v3)
- linear[((a1 * 64) + a2), ((a3 * 128) + a4)] += acc0
+ linear[((a1 * 64) + (a2 * 2)), ((a3 * 128) + (a4 * 2))] += acc0
+ linear[((a1 * 64) + (a2 * 2)), ((a3 * 128) + ((a4 * 2) + 1))] += acc1
+ linear[((a1 * 64) + ((a2 * 2) + 1)), ((a3 * 128) + (a4 * 2))] += acc2
+ linear[((a1 * 64) + ((a2 * 2) + 1)), ((a3 * 128) + ((a4 * 2) + 1))] += acc3
<<< t:008_register_tile
The thread axes shrink (a2:64→32, a4:128→64 — each thread now owns 2 × 2 outputs), the K-inner body fans out 4× in registers (4 FMAs per K-inner iteration against 4 shared-memory loads), and the trailing Write expands into 4 stores indexed by the per-thread register offsets. The production (8, 4) configuration follows the same pattern, with 32 FMAs against 12 smem loads, to achieve better arithmetic intensity.
Permute Register Tile
The register_tile rule raises arithmetic intensity by giving each thread a wider strip of B (F_N columns per K-iter). However, a wider strip means more shared-memory loads from the same row of B per K-iter. Adjacent columns of the slab alias to the same bank under the natural stride, so two back-to-back loads (eight scalar LDS.32 loads are vectorized into two LDS.128) on adjacent columns hit the same bank with different addresses — a 2-way conflict that doubles the load latency. The rule reorders the strip so the extra loads, so they hit different banks.
The Linear example with (F_M, F_N) = (8, 4) doesn't hit this — F_N = 4 fits one LDS.128 cleanly. The pass fires on shapes where the analyzer would otherwise project a real bank conflict (most matmul kernels with F_N ≥ 8). For TinyLlama at seq_len=32 the q/k/v/o projections all pick F_N = 8, and chunking visibly changes the body Loads and trailing accumulator stores:
deplodock compile TinyLlama/TinyLlama-1.1B-Chat-v1.0 \
--layer 0 --seq-len 32 --ir tile -vv \
| awk '/^>>> t:009/,/^<<< t:009/'
>>> t:009_permute_register_tile
@@ matched at linear_reduce (in-place) @@
for a5 in 0..32: # reduce
- in0 = load n13_smem[a5, (a3 * 8)]
- in1 = load n13_smem[a5, ((a3 * 8) + 1)]
- in2 = load n13_smem[a5, ((a3 * 8) + 2)]
- in3 = load n13_smem[a5, ((a3 * 8) + 3)]
- in4 = load n13_smem[a5, ((a3 * 8) + 4)]
- in5 = load n13_smem[a5, ((a3 * 8) + 5)]
- in6 = load n13_smem[a5, ((a3 * 8) + 6)]
- in7 = load n13_smem[a5, ((a3 * 8) + 7)]
+ in0 = load n13_smem[a5, (a3 * 4)]
+ in1 = load n13_smem[a5, ((a3 * 4) + 1)]
+ in2 = load n13_smem[a5, ((a3 * 4) + 2)]
+ in3 = load n13_smem[a5, ((a3 * 4) + 3)]
+ in4 = load n13_smem[a5, ((a3 * 4) + 64)] # +64 = next 4-strip
+ in5 = load n13_smem[a5, ((a3 * 4) + 65)]
+ in6 = load n13_smem[a5, ((a3 * 4) + 66)]
+ in7 = load n13_smem[a5, ((a3 * 4) + 67)]
...
- linear_reduce[0, (a1*8), 0, ((a2*128) + (a3*8))] += acc0
- linear_reduce[0, (a1*8), 0, ((a2*128) + (a3*8) + 1)] += acc1
+ linear_reduce[0, (a1*8), 0, ((a2*128) + (a3*4))] += acc0
+ linear_reduce[0, (a1*8), 0, ((a2*128) + (a3*4) + 1)] += acc1
...
- linear_reduce[0, (a1*8), 0, ((a2*128) + (a3*8) + 4)] += acc4
+ linear_reduce[0, (a1*8), 0, ((a2*128) + (a3*4) + 64)] += acc4
<<< t:009_permute_register_tile
The naive +0..+7 reads cluster into two LDS.128 phases that hit the same banks (8-way per-bank serialization across the warp), while the chunked +0..+3, +64..+67 pattern keeps each phase reading 4 contiguous fp32 (32 distinct banks per phase, no conflict). The matching shift in the accumulator stores keeps the output indexed correctly under the new register-tile layout.
Note on bank-conflict semantics: a conflict fires only when threads of one warp target different addresses on the same bank. If multiple threads happen to read the same address, the bank performs one fetch and broadcasts the value to every requesting lane in a single cycle, free of charge. That's why the visualizations below color the punch card cells by address (not by lane): a column of identically colored cells stacked on one bank is a broadcast and costs nothing; different colors stacked on one bank mean distinct addresses contending, and we pay one cycle per distinct address.
Top half: the warp's 32 lanes plotted by their target bank; same color in one column = one address (broadcast — no cost), different colors stacked = different addresses (serialized — bank conflict). Bottom half: the smem slab itself. Each cell is colored by the bank it sits in. The rule doesn't change the smem layout, so coloring is the same. The rule changes the access pattern. The eight highlighted columns mark the cells one specific Load (v0) reaches across the K loop. With chunking applied (right) those columns shift to land on different bank colors, eliminating conflicts.
Double Buffer
K-outer iterations have a structural inefficiency: while the K-inner loop is doing arithmetic on slab k, the next slab k+1 is sitting idle in HBM. double_buffer promotes the K-outer Stages to BufferedStage with two shared-memory slots — while one is consumed, the other is filled.
DEPLODOCK_FM=2 DEPLODOCK_FN=2 deplodock compile \
-c "torch.nn.Linear(3584,3584,bias=False)(torch.randn(512,3584))" \
--target sm_120 --ir tile -vv \
| awk '/^>>> t:010/,/^<<< t:010/'
>>> t:010_double_buffer
@@ matched at linear (in-place) @@
Tile(axes=(a0:4=BLOCK, a1:8=BLOCK, a2:32=THREAD, a3:28=BLOCK, a4:64=THREAD)):
for a5 in 0..56: # free
- n1_smem = Stage(n1, ..., slab=(a6:16@0, a4:128@1))
- input_smem = Stage(input, ..., slab=(a2:64@0, a6:16@1))
+ n1_smem = BufferedStage(n1, ..., slab=(a6:16@0, a4:128@1)) buffers=2@(a5 % 2)
+ input_smem = BufferedStage(input, ..., slab=(a2:64@0, a6:16@1)) buffers=2@(a5 % 2)
for a6 in 0..16: # reduce
- in0 = load n1_smem[a6, (a4 * 2)]
- in1 = load n1_smem[a6, ((a4 * 2) + 1)]
- in2 = load input_smem[(a2 * 2), a6]
- in3 = load input_smem[((a2 * 2) + 1), a6]
+ in0 = load n1_smem[(a5 % 2), a6, (a4 * 2)]
+ in1 = load n1_smem[(a5 % 2), a6, ((a4 * 2) + 1)]
+ in2 = load input_smem[(a5 % 2), (a2 * 2), a6]
+ in3 = load input_smem[(a5 % 2), ((a2 * 2) + 1), a6]
...
<<< t:010_double_buffer
Stage → BufferedStage with buffers=2@(a5 % 2): two shared-memory slots indexed by K-outer loop variable mod 2. Every staged Load picks up the new leading index.
TMA Copy
TMA (Tensor Memory Accelerator) is a hardware unit introduced on Hopper (sm_90). Instead of every thread computing its own global-memory addresses and issuing per-element loads, the host pre-builds a tensor descriptor (CUtensorMap) that describes the operand's shape, stride, and tile box; at runtime a single thread issues one cp.async.bulk.tensor instruction and the hardware streams a multi-dimensional slab from HBM into shared memory — boundary handling, swizzling, and address arithmetic all done by the engine. See NVIDIA's CUDA Programming Guide — Asynchronous Data Copies for the full instruction-level reference covering both TMA and the older cp.async family.
Public cuBLAS kernels don't actually use
cp.async.bulk.tensorfor the operand load for FP32 kernels. They stick with acp.async-driven producer/consumer pipeline (the Ampere-era transport) even on Hopper / Blackwell. However, I had good results with TMA for fp32 SGEMM, so stick with it as the core path in the pipeline.
The tma_copy runs first and narrows both buffered Stages to TmaBufferedStage, so a single thread can issue a cp.async.bulk.tensor descriptor and the hardware streams the slab into shared memory.
DEPLODOCK_FM=2 DEPLODOCK_FN=2 deplodock compile \
-c "torch.nn.Linear(3584,3584,bias=False)(torch.randn(512,3584))" \
--target sm_120 --ir tile -vv \
| awk '/^>>> t:011/,/^<<< t:011/'
>>> t:011_tma_copy
@@ matched at linear (in-place) @@
Tile(axes=(a0:4=BLOCK, a1:8=BLOCK, a2:32=THREAD, a3:28=BLOCK, a4:64=THREAD)):
for a5 in 0..56: # free
- n1_smem = BufferedStage(n1, ..., slab=(a6:16@0, a4:128@1)) buffers=2@(a5 % 2)
- input_smem = BufferedStage(input, ..., slab=(a2:64@0, a6:16@1)) buffers=2@(a5 % 2)
+ n1_smem = TmaBufferedStage(n1, ..., slab=(a6:16@0, a4:128@1)) buffers=2@(a5 % 2) tma
+ input_smem = TmaBufferedStage(input, ..., slab=(a2:64@0, a6:16@1)) buffers=2@(a5 % 2) tma
+ AsyncWait(keep=0, phase=((a5 / 2) % 2), slot=(a5 % 2))
for a6 in 0..16: # reduce
in0 = load n1_smem[(a5 % 2), a6, (a4 * 2)]
...
<<< t:011_tma_copy
The Stage type flips BufferedStage → TmaBufferedStage for both operands. It is the IR-level marker the materializer reads to emit cp_async_bulk_tensor_2d instead of a plain cooperative copy. An AsyncWait appears immediately before the K-inner reduce body: it is the mbarrier wait that gates the consumer side of the producer/consumer handshake.
TMA descriptors require the slab origin and the inner-dim stride to satisfy NVIDIA's alignment rules (16-byte slab base, contiguous inner dim, box-dim shape compatible with the TMA box descriptor). When a stage misses any of those (small grids where the K-inner extent doesn't divide cleanly, batched-matmul shapes with non-contiguous inner strides, K-outer chunks below the descriptor's minimum), tma_copy skips that stage and async_copy picks it up instead.
A Note on Swizzling
There's a split_inner_for_swizzle pass in the stack (gated behind DEPLODOCK_TMA_SWIZZLE=1) that rewrites every smem Load with the inverse of TMA's Sw<3, M, S> permutation, so the kernel can read from a swizzle-shuffled slab without bank conflicts. It's off by default.
TMA's swizzle modes (B32 / B64 / B128) operate on a fixed 8-row × 32-bank tile and only rearrange addresses within that tile. Slabs for FP32 matmul are much larger than that. The inner-dim slab spans 128 fp32 columns, and the staged slab is hundreds of bytes wide along the bank-conflict-relevant axis. The bank conflicts at that scale come from the slab shape, not from the within-tile permutation, so swizzling the producer descriptor doesn't actually clear them.
Async Copy
On the sm_80 path (Ampere), tma_copy and split_inner_for_swizzle are both no-ops; async_copy is what narrows the Stages to AsyncBufferedStage. The emitted CUDA fills the slab with a per-thread cp.async.ca.shared.global loop closed by cp.async.commit_group. (NVIDIA's Asynchronous Data Copies page covers cp.async semantics alongside the TMA path linked from the previous section.)
deplodock compile \
-c "torch.nn.Linear(3584,3584,bias=False)(torch.randn(512,3584))" \
--target sm_80 --ir tile -vv \
| awk '/^>>> t:013/,/^<<< t:013/'
>>> t:013_async_copy
@@ matched at linear (in-place) @@
Tile(axes=(a0:4=BLOCK, a1:8=BLOCK, a2:8=THREAD, a3:28=BLOCK, a4:16=THREAD)):
for a5 in 0..56: # free
- p_weight_smem = BufferedStage(p_weight, ..., slab=(a4:128@0, a6:16@1)) buffers=2@(a5 % 2)
- input_smem = BufferedStage(input, ..., slab=(a2:64@0, a6:16@1)) buffers=2@(a5 % 2)
+ p_weight_smem = AsyncBufferedStage(p_weight, ..., slab=(a4:128@0, a6:16@1)) buffers=2@(a5 % 2) async
+ AsyncWait(keep=0)
+ input_smem = AsyncBufferedStage(input, ..., slab=(a2:64@0, a6:16@1)) buffers=2@(a5 % 2) async
+ AsyncWait(keep=0)
<<< t:013_async_copy
Stage → AsyncBufferedStage flip for both operands, plus a default AsyncWait(keep=0) after each producer that pipeline_k_outer will rewrite into a real cp.async.wait_group N rotation.
Pad Smem
For matmul, the B slab's column-major access patterns hit the same shared-memory bank from every thread of a warp. The pad_smem rule adds an extra column to break the alignment. It is visible in the IR as a pad= annotation on the eligible Stage:
deplodock compile \
-c "torch.nn.Linear(3584,3584,bias=False)(torch.randn(512,3584))" \
--target sm_80 --ir tile -vv \
| awk '/^>>> t:014/,/^<<< t:014/'
>>> t:014_pad_smem
@@ matched at linear (in-place) @@
- p_weight_smem = AsyncBufferedStage(p_weight, ..., slab=(a4:128@0, a6:16@1)) buffers=2@(a5 % 2) async
- input_smem = AsyncBufferedStage(input, ..., slab=(a2:64@0, a6:16@1)) buffers=2@(a5 % 2) async
+ p_weight_smem = AsyncBufferedStage(p_weight, ..., slab=(a4:128@0, a6:16@1)) pad=(0, 1) buffers=2@(a5 % 2) async
+ input_smem = AsyncBufferedStage(input, ..., slab=(a2:64@0, a6:16@1)) pad=(0, 1) buffers=2@(a5 % 2) async
<<< t:014_pad_smem
Both Stages pick up pad=(0, 1) — the bank-conflict analyzer projects column-major Loads against either slab clustering on the same bank, so the rule pads each. The materializer reads the pad=(0, 1) annotation and bumps the inner stride from 16 to 17 elements per row in the emitted code: p_weight_smem[a5 % 2 * 2176 + a4 * 4 * 17 + a6] (the * 17 instead of * 16 is the padded stride; the smem allocation is also 4352 floats instead of 4096).
The smem-layout ladder (bottom half of each column) makes the fix easy to see. Without padding (left), every row of the slab starts at the same bank — the slab is a stack of identical 32-bank-wide rows, so two threads accessing different rows at the same column always collide on one bank. With pad=(0, 1) (right), each row's bank assignment shifts by one relative to the row above (the "ladder" pattern). Now any two threads accessing the same column from different rows land on different banks.
Pipeline K-Outer
The pipeline_k_outer realizes the overlap that double_buffer set up. It applies to both AsyncBufferedStage (sm_80) and TmaBufferedStage (sm_120) — the rotation structure is the same; only the issue/wait primitives differ. The K-outer loop is rotated into prologue + steady-state + epilogue:
- Prologue — issue the transfer for the first slab; no compute yet.
- Steady-state — for each iteration
k, issue the transfer for slabk+1, wait on slabk, run K-inner compute against slabk. - Epilogue — wait on the last slab, run its compute, no more loads.
DEPLODOCK_FM=2 DEPLODOCK_FN=2 deplodock compile \
-c "torch.nn.Linear(3584,3584,bias=False)(torch.randn(512,3584))" \
--target sm_120 --ir tile -vv \
| awk '/^>>> t:015/,/^<<< t:015/'
>>> t:015_pipeline_k_outer
@@ matched at linear (in-place) @@
Tile(axes=(a0:4=BLOCK, a1:8=BLOCK, a2:32=THREAD, a3:28=BLOCK, a4:64=THREAD)):
- for a5 in 0..56: # free
- n1_smem = TmaBufferedStage(n1, origin=(((a0*56+a5)*16), (a3*128)), ...) buffers=2@(a5 % 2) tma
- input_smem = TmaBufferedStage(input, origin=((a1*64), ((a0*56+a5)*16)), ...) buffers=2@(a5 % 2) tma
- AsyncWait(keep=0, phase=((a5 / 2) % 2), slot=(a5 % 2))
- for a6 in 0..16: # reduce (K-inner FMAs)
- ...
+ n1_smem = TmaBufferedStage(n1, origin=((a0*56)*16, (a3*128)), ...) buffers=2@0 tma # prologue
+ input_smem = TmaBufferedStage(input, origin=((a1*64), (a0*56)*16), ...) buffers=2@0 tma
+ for a5 in 0..55: # free (steady-state — iterates 55 not 56)
+ AsyncWait(keep=2, phase=((a5 / 2) % 2), slot=(a5 % 2)) # wait on slab a5
+ for a6 in 0..16: # reduce (K-inner FMAs against slab a5)
+ ...
+ n1_smem = TmaBufferedStage(n1, origin=(((a0*56+(a5+1))*16), (a3*128)), ...) buffers=2@((a5+1) % 2) tma # issue slab a5+1
+ input_smem = TmaBufferedStage(input, origin=((a1*64), (((a0*56)+(a5+1))*16)), ...) buffers=2@((a5+1) % 2) tma
+ AsyncWait(keep=0, phase=1, slot=1) # epilogue: drain slab 55
+ for a6 in 0..16: # reduce (K-inner FMAs against slab 55)
+ ...
<<< t:015_pipeline_k_outer
Three structural changes. (1) The first-slab Stages are hoisted out above the loop as a prologue (2) The loop count drops from 56 to 55 because the last K-outer iteration moved to the epilogue. (3) Inside the steady-state body, the slab-issue Stages (now indexed (a5+1) % 2) appear after the K-inner FMAs, while the AsyncWait for slab a5 stays at the top — that's the rotation that lets the issue of slab a5+1 run concurrently with the compute on slab a5. The final AsyncWait drains slab 55 before the epilogue's K-inner body.
Mark Unroll
The mark_unroll rules annotates all small loops within the budget with an unroll flag. The diff is just the comment on the # reduce line gaining unroll. The materializer reads the flag and emits a #pragma unroll ahead of the for.
DEPLODOCK_FM=2 DEPLODOCK_FN=2 deplodock compile \
-c "torch.nn.Linear(3584,3584,bias=False)(torch.randn(512,3584))" \
--target sm_120 --ir tile -vv \
| awk '/^>>> t:016/,/^<<< t:016/'
>>> t:016_mark_unroll
@@ matched at linear (in-place) @@
@@ -5,5 +5,5 @@
for a5 in 0..55: # free
AsyncWait(keep=2, phase=((a5 / 2) % 2), slot=(a5 % 2))
- for a6 in 0..16: # reduce
+ for a6 in 0..16: # reduce unroll
in0 = load n1_smem[(a5 % 2), a6, (a4 * 2)]
in1 = load n1_smem[(a5 % 2), a6, ((a4 * 2) + 1)]
@@ -21,5 +21,5 @@
input_smem = TmaBufferedStage(input, origin=((a1 * 64), (((a0 * 56) + (a5 + 1)) * 16)), slab=(a2:64@0, a6:16@1)) buffers=2@((a5 + 1) % 2) tma
AsyncWait(keep=0, phase=1, slot=1)
- for a6 in 0..16: # reduce
+ for a6 in 0..16: # reduce unroll
in0 = load n1_smem[1, a6, (a4 * 2)]
in1 = load n1_smem[1, a6, ((a4 * 2) + 1)]
<<< t:016_mark_unroll
Final CUDA — Matmul sm_120
As in the diffs above, I keep (F_M, F_N) = (2, 2) for readability — production uses (8, 4), with the same kernel structure but a 32-FMA register tile and 32 stores instead of 4. I also shrink the per-CTA tile to (BM, BN) = (16, 16) so the readability override doesn't inflate the thread count past cp.async's 16-byte/thread budget — relevant for the sm_80 path below, and applied here too so both targets compile from the same launch geometry.
DEPLODOCK_FM=2 DEPLODOCK_FN=2 DEPLODOCK_BM=16 DEPLODOCK_BN=16 deplodock compile \
-c "torch.nn.Linear(3584,3584,bias=False)(torch.randn(512,3584))" \
--target sm_120 --ir tile -vv \
| grep -E '^>>> t:|^--- t:'
>>> t:001_tileify
>>> t:002_chunk_matmul_k
--- t:003_split_matmul_k skipped at linear: auto-picked splitK=1 (grid already fills the GPU or no useful split)
--- t:004_cooperative_reduce skipped at linear: Tile body has no reduce Loop
>>> t:005_blockify_launch
--- t:006_chunk_reduce skipped at linear: no non-matmul reduce Loop with stage-eligible fan-in needs chunking
>>> t:007_stage_inputs
>>> t:008_register_tile
--- t:009_permute_register_tile skipped at linear: no THREAD axis has Load-stride F divisible by 4 and > 4
>>> t:010_double_buffer
>>> t:011_tma_copy
--- t:012_split_inner_for_swizzle skipped at linear: DEPLODOCK_TMA_SWIZZLE not set
--- t:013_async_copy skipped at linear: no Stage eligible for cp.async (need >= 16 bytes/thread)
--- t:014_pad_smem skipped at linear: no Stage has a fixable bank conflict within slab budget
>>> t:015_pipeline_k_outer
>>> t:016_mark_unroll
The structural rules (tileify through register_tile) all fire; split_matmul_k skips because the 32 × 224 = 7168-CTA grid already saturates; permute_register_tile skips on the small F_N = 2 strip; tma_copy then narrows both BufferedStages to TmaBufferedStage, which makes async_copy redundant; pad_smem skips because the rule excludes TmaBufferedStage by construction (TMA box copies require the inner-dim stride to match the descriptor, so +1 padding would misalign body Loads against the box write); pipeline_k_outer rotates the K-outer loop into prologue + steady-state + epilogue.
I use inline PTX in codegen instead of intrinsics for TMA, mbarrier, and cp.async primitives to avoid dependency on
libcu++, and version-coupled compile-mode flags. Also, every PTX insert is stateless. The materializer emits a fixed string template per primitive with%0/%1/...operand placeholders, and the surrounding C scope feeds them in. There's no RAII state to maintain and lifetimes to worry about.
DEPLODOCK_FM=2 DEPLODOCK_FN=2 DEPLODOCK_BM=16 DEPLODOCK_BN=16 deplodock compile \
-c "torch.nn.Linear(3584,3584,bias=False)(torch.randn(512,3584))" \
--target sm_120 --ir cuda
struct __align__(64) CUtensorMap { unsigned long long opaque[16]; };
static __device__ __forceinline__ void mbarrier_init(
unsigned long long* mbar,
int count
) {
unsigned int addr = __cvta_generic_to_shared(mbar);
asm volatile(
"mbarrier.init.shared.b64 [%0], %1;\n"
::
"r"(addr),
"r"(count)
: "memory"
);
}
static __device__ __forceinline__ void mbarrier_arrive_expect_tx(
unsigned long long* mbar,
int bytes
) {
unsigned int addr = __cvta_generic_to_shared(mbar);
unsigned long long state;
asm volatile(
"mbarrier.arrive.expect_tx.shared.b64 %0, [%1], %2;\n"
: "=l"(state)
: "r"(addr),
"r"(bytes)
: "memory"
);
}
static __device__ __forceinline__ void mbarrier_wait_parity(
unsigned long long* mbar,
int phase
) {
// Issue one ``mbarrier.try_wait`` first — its hint timeout makes
// the warp suspend rather than spin while the TMA tx drains,
// freeing the scheduler to run other warps. The PTX-level
// ``while !try_wait`` loop is required (try_wait can return early);
// the suspend hint prevents hot-spinning across all CTA threads
// (~3-4× kernel speedup on small matmuls where the wait-vs-compute
// ratio is high).
unsigned int addr = __cvta_generic_to_shared(mbar);
asm volatile(
"{.reg .pred P;"
" bw: mbarrier.try_wait.parity.shared.b64 P, [%0], %1;"
" @!P bra bw;}\n"
::
"r"(addr),
"r"(phase)
);
}
static __device__ __forceinline__ void cp_async_bulk_tensor_2d(
void* smem,
const CUtensorMap* desc,
int c0,
int c1,
unsigned long long* mbar
) {
unsigned int saddr = __cvta_generic_to_shared(smem);
unsigned int maddr = __cvta_generic_to_shared(mbar);
asm volatile(
"cp.async.bulk.tensor.2d.shared::cta.global"
".mbarrier::complete_tx::bytes "
"[%0], [%1, {%2, %3}], [%4];\n"
::
"r"(saddr),
"l"(desc),
"r"(c0),
"r"(c1),
"r"(maddr)
: "memory"
);
}
// (cp_async_bulk_tensor_3d/4d/5d emitted alongside;
// omitted here — unused for this 2D matmul.)
extern "C" __global__
__launch_bounds__(64) void k_linear_reduce(
const float* n1,
const float* input,
float* linear,
const CUtensorMap* __restrict__ n1_smem_desc,
const CUtensorMap* __restrict__ input_smem_desc
) {
int a0 = blockIdx.x / 224;
int a2 = blockIdx.x % 224;
int a1 = threadIdx.x / 8;
int a3 = threadIdx.x % 8;
__shared__ unsigned long long tma_mbar[2];
if (threadIdx.x == 0) {
mbarrier_init(&tma_mbar[0], 2);
mbarrier_init(&tma_mbar[1], 2);
}
__syncthreads();
float acc0 = 0.0f;
float acc1 = 0.0f;
float acc2 = 0.0f;
float acc3 = 0.0f;
__shared__ __align__(128) float n1_smem[1024];
if (threadIdx.x == 1) {
mbarrier_arrive_expect_tx(&tma_mbar[0], 2048);
cp_async_bulk_tensor_2d(
&n1_smem[0],
n1_smem_desc,
a2 * 16,
0,
&tma_mbar[0]
);
}
__shared__ __align__(128) float input_smem[1024];
if (threadIdx.x == 0) {
mbarrier_arrive_expect_tx(&tma_mbar[0], 2048);
cp_async_bulk_tensor_2d(
&input_smem[0],
input_smem_desc,
0,
a0 * 16,
&tma_mbar[0]
);
}
for (int a4 = 0; a4 < 111; a4++) {
mbarrier_wait_parity(&tma_mbar[a4 % 2], a4 / 2 % 2);
#pragma unroll
for (int a5 = 0; a5 < 32; a5++) {
float2 _v_in0 = *reinterpret_cast<const float2*>(
&n1_smem[a4 % 2 * 512 + a5 * 16 + a3 * 2]);
float in0 = _v_in0.x;
float in1 = _v_in0.y;
float in2 = input_smem[a4 % 2 * 512 + a1 * 2 * 32 + a5];
float in3 = input_smem[a4 % 2 * 512 + (a1 * 2 + 1) * 32 + a5];
float v0 = in2 * in0;
float v1 = in2 * in1;
float v2 = in3 * in0;
float v3 = in3 * in1;
acc0 += v0;
acc1 += v1;
acc2 += v2;
acc3 += v3;
}
if (threadIdx.x == 1) {
mbarrier_arrive_expect_tx(&tma_mbar[(a4 + 1) % 2], 2048);
cp_async_bulk_tensor_2d(
&n1_smem[(a4 + 1) % 2 * 512],
n1_smem_desc,
a2 * 16,
(a4 + 1) * 32,
&tma_mbar[(a4 + 1) % 2]
);
}
if (threadIdx.x == 0) {
mbarrier_arrive_expect_tx(&tma_mbar[(a4 + 1) % 2], 2048);
cp_async_bulk_tensor_2d(
&input_smem[(a4 + 1) % 2 * 512],
input_smem_desc,
(a4 + 1) * 32,
a0 * 16,
&tma_mbar[(a4 + 1) % 2]
);
}
}
mbarrier_wait_parity(&tma_mbar[1], 1);
#pragma unroll
for (int a5 = 0; a5 < 32; a5++) {
float2 _v_in0 = *reinterpret_cast<const float2*>(
&n1_smem[512 + a5 * 16 + a3 * 2]);
float in0 = _v_in0.x;
float in1 = _v_in0.y;
float in2 = input_smem[512 + a1 * 2 * 32 + a5];
float in3 = input_smem[512 + (a1 * 2 + 1) * 32 + a5];
float v0 = in2 * in0;
float v1 = in2 * in1;
float v2 = in3 * in0;
float v3 = in3 * in1;
acc0 += v0;
acc1 += v1;
acc2 += v2;
acc3 += v3;
}
linear[(a0 * 16 + a1 * 2) * 3584 + (a2 * 16 + a3 * 2)] = acc0;
linear[(a0 * 16 + a1 * 2) * 3584 + (a2 * 16 + (a3 * 2 + 1))] = acc1;
linear[(a0 * 16 + (a1 * 2 + 1)) * 3584 + (a2 * 16 + a3 * 2)] = acc2;
linear[(a0 * 16 + (a1 * 2 + 1)) * 3584 + (a2 * 16 + (a3 * 2 + 1))] = acc3;
}
Two TMA descriptors (one for each operand) are filled by the host once per launch and passed as __restrict__ kernel parameters; the kernel itself never touches HBM directly — every load is cp.async.bulk.tensor into smem and every FMA is against the staged slab. The n1_smem Load is vectorized to a float2 because F_N = 2 adjacent columns are read per iteration; the materializer recognizes contiguous-stride pairs and emits a single 64-bit LDS.64. With BM = BN = 16 the natural 32 × 224 = 7168-CTA grid already saturates the SMs, so split_matmul_k skips and the stores are plain = instead of atomicAdd.
Final CUDA — Matmul sm_80
Pass --target sm_80 and the same passes lower to a kernel of identical schedule but Ampere transport. The compute body is byte-identical: same 2 × 2 register tile, same K-inner unroll, same accumulator shape. The slab-fill path is a per-thread cp.async.ca.shared.global loop closed by cp.async.commit_group, with the K-outer loop rotated into prologue + steady-state + epilogue. The kernel signature also drops the two CUtensorMap* parameters.
DEPLODOCK_FM=2 DEPLODOCK_FN=2 DEPLODOCK_BM=16 DEPLODOCK_BN=16 deplodock compile \
-c "torch.nn.Linear(3584,3584,bias=False)(torch.randn(512,3584))" \
--target sm_80 --ir tile -vv \
| grep -E '^>>> t:|^--- t:'
>>> t:001_tileify
>>> t:002_chunk_matmul_k
--- t:003_split_matmul_k skipped at linear: auto-picked splitK=1 (grid already fills the GPU or no useful split)
--- t:004_cooperative_reduce skipped at linear: Tile body has no reduce Loop
>>> t:005_blockify_launch
--- t:006_chunk_reduce skipped at linear: no non-matmul reduce Loop with stage-eligible fan-in needs chunking
>>> t:007_stage_inputs
>>> t:008_register_tile
--- t:009_permute_register_tile skipped at linear: no THREAD axis has Load-stride F divisible by 4 and > 4
>>> t:010_double_buffer
--- t:011_tma_copy skipped at linear: TMA disabled (DEPLODOCK_TMA=0 or compute capability < sm_90)
--- t:012_split_inner_for_swizzle skipped at linear: DEPLODOCK_TMA_SWIZZLE not set
>>> t:013_async_copy
>>> t:014_pad_smem
>>> t:015_pipeline_k_outer
>>> t:016_mark_unroll
Two differences from the sm_120 trace:
tma_copyskips because TMA requires sm_90+, so the BufferedStages stay unnarrowed forasync_copyto pick up.pad_smemfires here where it skipped on sm_120.
The other rules (split_matmul_k, permute_register_tile, split_inner_for_swizzle) skip for the same reasons as on sm_120.
DEPLODOCK_FM=2 DEPLODOCK_FN=2 DEPLODOCK_BM=16 DEPLODOCK_BN=16 deplodock compile \
-c "torch.nn.Linear(3584,3584,bias=False)(torch.randn(512,3584))" \
--target sm_80 --ir cuda
extern "C" __global__
__launch_bounds__(64) void k_linear_reduce(
const float* p_weight,
const float* input,
float* linear
) {
int a0 = blockIdx.x / 224;
int a2 = blockIdx.x % 224;
int a1 = threadIdx.x / 8;
int a3 = threadIdx.x % 8;
float acc0 = 0.0f, acc1 = 0.0f, acc2 = 0.0f, acc3 = 0.0f;
// 2 buffers × 16 rows × 17 fp32 (pad=1 → stride 17)
__shared__ float p_weight_smem[544];
__shared__ float input_smem[544];
// prologue: kick off cp.async for slab 0
for (int f = a1 * 8 + a3; f < 256; f += 64) {
unsigned int saddr = __cvta_generic_to_shared(
&p_weight_smem[f / 16 * 17 + f % 16]
);
asm volatile(
"cp.async.ca.shared.global [%0], [%1], 4;\n"
::
"r"(saddr),
"l"(&p_weight[(a2 * 16 + f / 16) * 3584 + f % 16])
: "memory"
);
}
asm volatile("cp.async.commit_group;\n" ::: "memory");
for (int f = a1 * 8 + a3; f < 256; f += 64) {
unsigned int saddr = __cvta_generic_to_shared(
&input_smem[f / 16 * 17 + f % 16]
);
asm volatile(
"cp.async.ca.shared.global [%0], [%1], 4;\n"
::
"r"(saddr),
"l"(&input[(a0 * 16 + f / 16) * 3584 + f % 16])
: "memory"
);
}
asm volatile("cp.async.commit_group;\n" ::: "memory");
// steady-state: 223 of 224 K-outer chunks
for (int a4 = 0; a4 < 223; a4++) {
// issue slab a4+1 in parallel with compute on slab a4
for (int f = a1 * 8 + a3; f < 256; f += 64) {
unsigned int saddr = __cvta_generic_to_shared(
&p_weight_smem[(a4 + 1) % 2 * 272 + f / 16 * 17 + f % 16]
);
asm volatile(
"cp.async.ca.shared.global [%0], [%1], 4;\n"
::
"r"(saddr),
"l"(&p_weight[
(a2 * 16 + f / 16) * 3584
+ ((a4 + 1) * 16 + f % 16)
])
: "memory"
);
}
asm volatile("cp.async.commit_group;\n" ::: "memory");
for (int f = a1 * 8 + a3; f < 256; f += 64) {
unsigned int saddr = __cvta_generic_to_shared(
&input_smem[(a4 + 1) % 2 * 272 + f / 16 * 17 + f % 16]
);
asm volatile(
"cp.async.ca.shared.global [%0], [%1], 4;\n"
::
"r"(saddr),
"l"(&input[
(a0 * 16 + f / 16) * 3584
+ ((a4 + 1) * 16 + f % 16)
])
: "memory"
);
}
asm volatile("cp.async.commit_group;\n" ::: "memory");
asm volatile("cp.async.wait_group 2;\n" ::: "memory");
__syncthreads();
#pragma unroll
for (int a5 = 0; a5 < 16; a5++) {
float in0 = p_weight_smem[a4 % 2 * 272 + a3 * 2 * 17 + a5];
float in1 = p_weight_smem[a4 % 2 * 272 + (a3 * 2 + 1) * 17 + a5];
float in2 = input_smem[a4 % 2 * 272 + a1 * 2 * 17 + a5];
float in3 = input_smem[a4 % 2 * 272 + (a1 * 2 + 1) * 17 + a5];
acc0 += in2 * in0; acc1 += in2 * in1;
acc2 += in3 * in0; acc3 += in3 * in1;
}
}
// epilogue: drain final slab and run its compute
asm volatile("cp.async.wait_group 0;\n" ::: "memory");
__syncthreads();
#pragma unroll
for (int a5 = 0; a5 < 16; a5++) {
/* elided for length — body is byte-identical to the steady-state
K-inner above, with the slot index `a4 % 2` replaced by `1`
(the parity of the final slab) */
}
linear[(a0 * 16 + a1 * 2) * 3584 + (a2 * 16 + a3 * 2)] = acc0;
linear[(a0 * 16 + a1 * 2) * 3584 + (a2 * 16 + (a3 * 2 + 1))] = acc1;
linear[(a0 * 16 + (a1 * 2 + 1)) * 3584 + (a2 * 16 + a3 * 2)] = acc2;
linear[(a0 * 16 + (a1 * 2 + 1)) * 3584 + (a2 * 16 + (a3 * 2 + 1))] = acc3;
}
Kernel IR
Tile IR is platform-aware but still abstract: it carries Stage, BufferedStage, TmaBufferedStage, Combine, StridedLoop — schedule decisions, not hardware primitives. The next pass walks the fully-scheduled TileOp and emits a KernelOp whose body is one-to-one with the CUDA source it lowers to: Smem, Sync, CpAsyncCopy / CpAsyncCommit / CpAsyncWait, MbarrierInit / MbarrierArriveExpectTx / MbarrierWait, TmaDescriptor / TmaLoad, WarpShuffle, TreeHalve. CUDA emission is then a tree walk over those.
Most of the lowering is mechanical: a BufferedStage becomes a Smem allocation plus a per-iteration cooperative copy loop (or a TmaLoad for TmaBufferedStage); an AsyncWait becomes a CpAsyncWait + Sync; a Stage consumed by Loads becomes the same Smem block with the consumer Loads rewritten to read from it.
The one specialization worth calling out is Combine → WarpShuffle + TreeHalve. The materializer expands it into a warp-level butterfly via __shfl_xor_sync (the WarpShuffle primitive), staging warp partials into an acc_smem[NUM_WARPS] buffer and finishing with a TreeHalve block-level tree-merge through shared memory. This is the canonical block-wide reduction CUTLASS hand-writes for softmax / RMSNorm / SDPA-reduce.
RMSNorm is the cleanest example to see the rewrite. Tile IR — Stage + Combine:
deplodock compile \
-c "torch.nn.RMSNorm(2048)(torch.randn(1,32,2048))" \
--target sm_120 --ir tile
v0 = reciprocal(2048)
Tile(axes=(a0:256=THREAD, a1:32=BLOCK)):
x_smem = Stage(x, origin=(0, a1, 0), slab=(a2:2048@2))
StridedLoop(a2 = a0; < 2048; += 256): # reduce
in2 = load x_smem[a2]
v1 = multiply(in2, in2)
acc0 <- add(acc0, v1)
Combine(acc0, op=add)
v2 = multiply(acc0, v0)
v3 = add(v2, 1e-06)
v4 = rsqrt(v3)
StridedLoop(a2 = a0; < 2048; += 256): # free
in3 = load x_smem[a2]
in4 = load p_weight[a2]
v5 = multiply(in3, v4)
v6 = multiply(v5, in4)
rms_norm[0, a1, a2] = v6
Kernel IR — Smem allocation + cooperative fill + WarpShuffle + TreeHalve:
deplodock compile \
-c "torch.nn.RMSNorm(2048)(torch.randn(1,32,2048))" \
--target sm_120 --ir kernel
v0 = reciprocal(2048)
Tile(axes=(a0:256=THREAD, a1:32=BLOCK)):
Init(acc0, op=add)
Smem x_smem[2048] (float)
StridedLoop(x_smem_flat = a0; < 2048; += 256): # free
x_smem_v = load x[0, a1, (0 + x_smem_flat)]
x_smem[x_smem_flat] = x_smem_v
Sync
StridedLoop(a2 = a0; < 2048; += 256): # reduce
in2 = load x_smem[a2]
v1 = multiply(in2, in2)
acc0 <- add(acc0, v1)
WarpShuffle(acc0_w <- acc0, op=add, length=32)
Smem acc0_smem[8] (float)
if ((lane == 0)):
acc0_smem[warp] = acc0_w
Sync
TreeHalve(acc0_smem, op=add, length=8, tid=warp)
acc0_b = load acc0_smem[0]
v2 = multiply(acc0_b, v0)
v3 = add(v2, 1e-06)
v4 = rsqrt(v3)
StridedLoop(a2 = a0; < 2048; += 256): # free
in3 = load x_smem[a2]
in4 = load p_weight[a2]
v5 = multiply(in3, v4)
v6 = multiply(v5, in4)
rms_norm[0, a1, a2] = v6
Three things changed between the two listings:
- The
Stage(x, ...)declaration on the Tile IR side becomes an explicitSmem x_smem[2048]allocation plus a cooperative fill loop on the Kernel IR side — the materializer expands the Stage into its concrete primitives. - The
Combine(acc0, op=add)line expands to a warp-butterflyWarpShufflefollowed by a per-warp partial write intoacc0_smem, aSync, and aTreeHalveblock-level merge. - Explicit
Init(acc0, op=add)andSyncstatements appear where the Tile IR relied on structural conventions.
CUDA
The CUDA emitter is a tree walk over Kernel IR: every Kernel IR statement maps to either one CUDA statement or one inline-PTX asm volatile block.
The one piece of work the emitter still does is LDS.64 and LDS.128 vectorization. Kernel IR carries no float2 / float4 annotation; instead, the renderer detects consecutive scalar Load patterns (same operand, consecutive +0..+N-1 inner-element offsets) and folds them into a single *reinterpret_cast<const float{n}*>(&buf[base]) read at print time; nvcc would vectorize the scalar version too, adding this pass was a defensive move.
Validation
I run two benchmark sets: an end-to-end transformer-block latency on TinyLlama-1.1B and Qwen2.5-7B, and a per-kernel latency table against PyTorch eager + torch.compile to localize where time is spent. Both are FP32 on the RTX 5090; FP16 / TF32 / TF16-tensor-core paths are intentionally not covered yet.
Full Transformer Block
| Model | seq | Eager | torch.compile | Deplodock |
|---|---|---|---|---|
| TinyLlama-1.1B | 32 | 432 µs | 217 µs (2.00×) | 329 µs (1.31×) |
| TinyLlama-1.1B | 128 | 606 µs | 446 µs (1.36×) | 516 µs (1.18×) |
| TinyLlama-1.1B | 512 | 1262 µs | 1154 µs (1.09×) | 1946 µs (0.65×) |
| Qwen2.5-7B | 32 | 1106 µs | 949 µs (1.16×) | 880 µs (1.26×) |
| Qwen2.5-7B | 128 | 1566 µs | 1509 µs (1.04×) | 1441 µs (1.09×) |
| Qwen2.5-7B | 512 | 4963 µs | 4773 µs (1.04×) | 6187 µs (0.80×) |
At small sequence lengths (32 / 128) deplodock matches or slightly beats eager: the per-kernel wins on small reductions and small projections add up across the block. At seq=512 deplodock loses on both models: the dense matmul shapes (gate / up / down at the wide hidden dim) are still slower than cuBLAS implementations, and at long sequence the block is matmul-dominated.
torch.compile (Inductor) is the strong baseline here — it's competitive or ahead of eager at every shape, with the biggest win at TinyLlama-32 (2.00×) where its fused softmax + attention path beats eager's per-op dispatch. Deplodock matches or beats Inductor on Qwen-32 and Qwen-128.
Per-kernel Benchmarks
Per-kernel timings against PyTorch eager (cuBLAS / cuDNN under the hood) on every op shape used by TinyLlama and Qwen2.5-7B blocks. ratio = torch_us / depl_us; >1.00x means deplodock is faster, <1.00x means slower. Run on:
- GPU: NVIDIA GeForce RTX 5090 (sm_120, Blackwell)
- Driver: 580.126.09
- CUDA: 13.0 (
nvcc release 13.0, V13.0.88) - PyTorch: 2.11.0+cu130, cuDNN 9.19
The fully lowered Tile IR stack matches eager PyTorch on average and wins by a hair on the median shape (geomean 1.11x, median 1.04x).
The worst case is silu_mul_matmul fused down_proj at seq=512 ((1,512,18944) × (1,512,18944) × (18944,3584)) at 0.25x. In this case the complex SILU computations logic saturates the SFU and starves following matmul kernel, and extra registers lower the occupancy. A proper fix would involve using setmaxnreg and warp specialization, but I decided to leave those features for the future.
The dense matmul shapes (gate_proj / up_proj / down_proj at seq=512) sit at 0.67x–0.94x. Deplodock incorporates a simple heuristic for determining optimal matmul parameters, so many of those kernels suffer from underutilization.
The smaller k/v projections ((*, 256)) win up to 4.68x. RMSNorm, softmax, SDPA, and silu_mul are wins across the board — these are the kernels where launch overhead, the cooperative reduction, and smem staging dominate over raw FMA throughput, and that's where the Tile IR rewrites pay back the most.
Measuing against torch.compile (Inductor) changes the win/loss distribution, but doesn't change the geomean (1.20x) and median (0.98x) a lot. On large attention/SDPA shapes Inductor wins decisively over eager (sdpa.{qwen,tinyllama}.s128/s512: 1.8–2.9× speedup; large softmax: 1.7–2.1×) and roughly matches deplodock. On small RMSNorm / softmax / kv_proj kernels Inductor regresses sharply against eager (softmax.qwen.s32: 7.1× slowdown, rmsnorm.qwen.s32: 4.5× slowdown, launch overhead dominates the per-op time), and deplodock cleans up by 3–10× on those.
A note on the comparison's stability: re-running the same suite against PyTorch nightly (2.13.0.dev, cuDNN 9.20) shifts the eager-baseline geomean to ~1.53x and median to ~1.17x — most of the swing comes from the eager-PyTorch side (cuBLAS heuristics drift between releases), not deplodock, whose absolute kernel timings stay within ~10% across both setups. The numbers below are the most conservative read.
How to Close the Gap
There are a few important features that Deplodock currently omits to keep the implementation manageable:
-
Autotuning over Tile IR. Knobs like
chunk_matmul_kchunk size,blockify_launchthreads-per-block, andregister_tileshape are heuristics today. Tile-IR rewrites are pure functions of their parameters, so a search loop plugs in directly. It is the cheapest route to close the seq=512 dense-matmul gap. -
Warp specialization. Dedicate one warp (producer) to TMA issue + mbarrier waits, the rest (consumers) to FMAs against the staged slabs. The producer needs a tiny register file; the consumers get a wide one — unlocking larger register tiles and tighter pipelining than the current symmetric scheme.
-
Flash Attention. SDPA today lowers as three kernels —
Q @ Kᵀ, masked softmax,attn @ V— with the scores materialized through smem. Flash Attention fuses them via an online-softmax recurrence so scores stay in registers. Mechanically a Loop IR rewrite: recognize matmul-reduce-matmul on the same K axis, add running max + sum, fold the second matmul into the same K-outer loop. Gets attention from O(N²) to O(N) memory traffic. -
FP16 + tensor cores. Codegen is FP32 SIMT today (
FFMAonly, noMMA). Real ML workloads need FP16 / BF16 / FP8 through tensor cores:mma.syncon sm_80+,wgmma.mma_asyncon sm_90+. The lift is a newMmaTileKernel-IR primitive plus a Tile-IR rule that lowers half-precision matmul to the tensor-core path instead of FMA.
Closing Notes
The headline of this post is that a manageable compiler stack: six IRs, sixteen Tile-IR rules, ~8K lines of Python, can match and on some shapes beat a production stack like PyTorch eager + Inductor on specific model architectures. Geomean 1.11x against eager, 1.20x against torch.compile, full-block parity at TinyLlama-128 and Qwen-128 on FP32.
The pass stack itself looks most intimidating from the outside, though, in reality it is composed of simple targeted rules that observe one fact about the kernel structure and improve it. The three running examples are the whole story: the same sixteen rules, applied to three different starting IRs, produce three different final kernels, with no kernel-specific code anywhere.
If you made it this far, clone the compiler and run deplodock compile <hf_model> --ir tile on a model of your choice.
References
Series
- Dmitry Trifonov. Building a GPU Compiler From Scratch — Part 1. CloudRift blog. The first half of this pipeline: Loop IR, the upper passes, and the RMSNorm walk-through that this post picks up from.
- Dmitry Trifonov. Building a GPU Compiler From Scratch — Part 3. CloudRift blog. SP-MCTS autotuning over the Tile-IR rule parameter packs introduced here; SQLite-backed cache +
deplodock tune/deplodock run --tune-dbintegration; per-kernel speedups against eager andtorch.compile.
GPU programming primers
- Dmitry Trifonov. Evolution of GPU Programming. CloudRift blog. The conceptual arc from pixel shaders to modern CUDA; useful background for the execution and memory model this post assumes throughout.
- NVIDIA. CUDA C++ Programming Guide, chapters 2 ("Programming Model") and 3 ("Programming Interface"). The canonical reference for threads, blocks, warps, shared memory, and the kernel launch model that Tile IR encodes as axis bindings and
Tileops. - Simon Boehm. How to Optimize a CUDA Matmul Kernel for cuBLAS-like Performance. A step-by-step build-up of an SGEMM kernel through tiling, shared-memory staging, register tiles, and pipelining — the same progression Tile IR mechanizes via small rewrite rules.
Halide-style scheduling
- Jonathan Ragan-Kelley, Connelly Barnes, Andrew Adams, Sylvain Paris, Frédo Durand, Saman Amarasinghe. Halide: A Language and Compiler for Optimizing Parallelism, Locality, and Recomputation in Image Processing Pipelines. PLDI 2013. The algorithm/schedule split that the Loop IR / Tile IR boundary in this compiler mirrors.
- Tianqi Chen et al. TVM: An Automated End-to-End Optimizing Compiler for Deep Learning. OSDI 2018. Auto-tuned extension of Halide-style scheduling; the natural reference for what an autotuner over Tile IR rewrites would look like.
- Philippe Tillet, H. T. Kung, David Cox. Triton: An Intermediate Language and Compiler for Tiled Neural Network Computations. MAPL 2019. The block-programming language Inductor lowers to. Sits at roughly the abstraction level of our Tile IR, but with a Pythonic surface and an LLVM backend instead of source emission.
GPU memory hierarchy and asynchronous copies
- NVIDIA. CUDA Programming Guide — Asynchronous Data Copies. The unified reference for both
cp.async(Ampere+) andcp.async.bulk.tensor/ TMA (Hopper+); directly mirrored byasync_copy,tma_copy, andpipeline_k_outer. - NVIDIA. Hopper Tuning Guide — TMA and Tensor Memory Accelerator. Hopper-specific tuning notes for the TMA path; complements the programming-guide reference above.
- Vasily Volkov. Better Performance at Lower Occupancy. GTC 2010. The original argument for register tiling over occupancy — directly applicable to
register_tile.
Matmul codegen and CUTLASS
- NVIDIA. CUTLASS: CUDA Templates for Linear Algebra Subroutines. The reference implementation of the patterns this compiler emits a simplified version of: CTA tiling, double-buffered shared-memory pipelines, TMA-driven producer/consumer schedules.
- Dmitry Trifonov. Beating cuBLAS on RTX 5090. CloudRift blog. A walk-through of the hand-tuned SGEMM kernel this compiler is approaching from the codegen side; the SASS-level analysis there is what closing the remaining matmul gap requires.
Polyhedral scheduling
- Uday Bondhugula, Albert Hartono, J. Ramanujam, P. Sadayappan. A Practical Automatic Polyhedral Parallelizer and Locality Optimizer. PLDI 2008. Pluto's ILP-based scheduler over the polyhedral model. A search-based replacement for the heuristic ordering of our pass stack.
- Nicolas Vasilache et al. Tensor Comprehensions: Framework-Agnostic High-Performance Machine Learning Abstractions. arXiv:1802.04730, 2018. The first major ML compiler built directly on the polyhedral model; the reference for unifying fusion and scheduling into one search space.